AIGC动态欢迎阅读
原标题:今日arXiv最热大模型论文:上海AI lab发布MathBench,GPT-4o的数学能力有多强?
关键字:模型,数学,问题,能力,阶段
文章来源:夕小瑶科技说
内容字数:8326字
内容摘要:
夕小瑶科技说 原创作者 | 谢年年大模型数学能力哪家强?
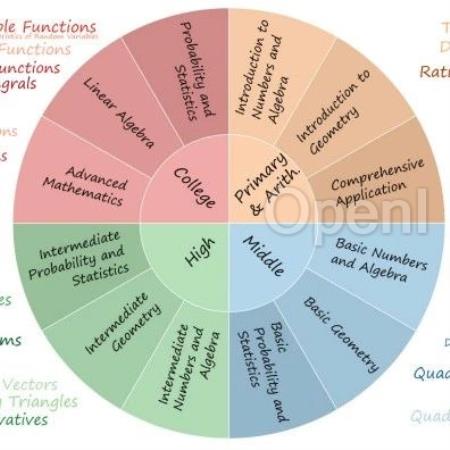
最近,上海AI lab构建了一个全面的多语言数学基准——MathBench。与现有的基准不同的是,MathBench涵盖从小学、初中、高中、大学不同难度,从基础算术题到高阶微积分、统计学、概率论等丰富类别的数学题目,跨度大,难度设置呈阶梯状,可以多维度评估模型的数学能力。
本文测试了20+个开源或闭源不同规模的大模型,包括新秀GPT-4o、常胜将军GPT-4,还有开源模型里的扛把子通义千问和llama-3。
一起来看看各家大模型的数学真实水平到底如何吧~
论文标题:MathBench: Evaluating the Theory and Application Proficiency of LLMs with a Hierarchical Mathematics Benchmark
论文链接:https://arxiv.org/pdf/2405.12209
Github连接: https://github.com/open-compass/MathBench
方法1. 预定义知识框架在MathBench中,作者首先将数学内容分为
原文链接:今日arXiv最热大模型论文:上海AI lab发布MathBench,GPT-4o的数学能力有多强?
联系作者
文章来源:夕小瑶科技说
作者微信:xixiaoyaoQAQ
作者简介:专业、有趣、深度价值导向的科技媒体。聚集30万AI工程师、研究员,覆盖500多家海内外机构投资人,互联网大厂中高管和AI公司创始人。一线作者来自清北、国内外顶级AI实验室和大厂,兼备敏锐的行业嗅觉和洞察深度。商务合作:zym5189
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。