AIGC动态欢迎阅读
原标题:任意模态输入输出?语音/文本/图像/音乐都拿下! 复旦提出AnyGPT:序列建模的统一多模态 LLM
关键字:解读,数据,文本,图像,模型
文章来源:算法邦
内容字数:10275字
内容摘要:
直播预告 | 5月28日10点,「智猩猩AI新青年讲座」第236讲正式开讲,密歇根大学安娜堡分校在读博士生张挥杰将直播讲解《利用多级框架和多解码器架构提高扩散模型训练效率》,欢迎扫名~导读本文提出 AnyGPT,一种 any-to-any 的多模态大语言模型。采用离散的表征统一处理语音、文本、图像和音乐等多种不同模态信号。文章构建了一个多模态,以文本为中心的数据集 AnyInstruct-108k。该数据集利用生成模型合成,是一个大规模多模态指令数据集。本文目录
1 AnyGPT:序列建模的统一多模态 LLM
(来自复旦大学,上海 AI Lab)
1 AnyGPT 论文解读
1.1 从多模态输入文本输出,到多模态输入多模态输出
1.2 AnyGPT 多模态分词器
1.3 AnyGPT 基座模型
1.4 AnyGPT 生成过程
1.5 AnyGPT 数据集
1.6 实验结果
太长不看版
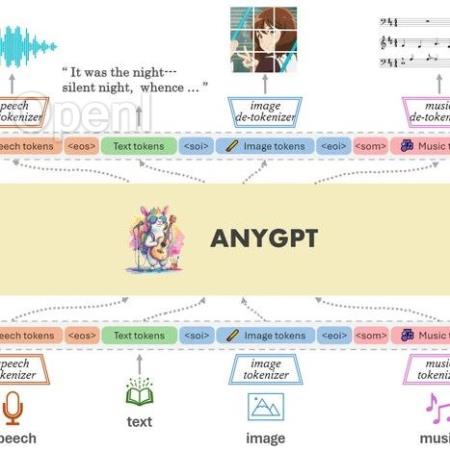
AnyGPT 是一种 any-to-any 的多模态大语言模型,它可以处理多种模态数据,包括语音、文本、图像和音乐。不同于之前的多模态大模型的点是 AnyGPT 使用了 LLM 的架构和范式。但是与
原文链接:任意模态输入输出?语音/文本/图像/音乐都拿下! 复旦提出AnyGPT:序列建模的统一多模态 LLM
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。