AIGC动态欢迎阅读
原标题:大模型国产化适配4-基于昇腾910使用LLaMA-13B进行多机多卡训练
关键字:华为,模型,权重,数据,路径
文章来源:算法邦
内容字数:0字
内容摘要:
直播预告 | 6月6日晚7点,「智猩猩AI新青年讲座」第238讲正式开讲,香港大学CVMI Lab在读博士 杨霁晗将直播讲解《V-IRL:根植于真实世界的AI Agents》,欢迎扫名~随着 ChatGPT 的现象级走红,引领了 AI 大模型时代的变革,从而导致 AI 算力日益紧缺。与此同时,中美贸易战以及美国对华进行AI芯片相关的制裁导致 AI 算力的国产化适配势在必行。之前讲述了基于昇腾910使用ChatGLM-6B进行模型训练和推理,主要是针对 MindSpore 框架进行大模型训练,这也是华为自家研发的 AI 框架。在昇腾上面除了使用 MindSpore 进行大模型训练,我们也可以使用 PyTorch 进行大模型训练。这两个框架也是在昇腾 NPU 上华为花主要精力维护的两款 AI 框架。
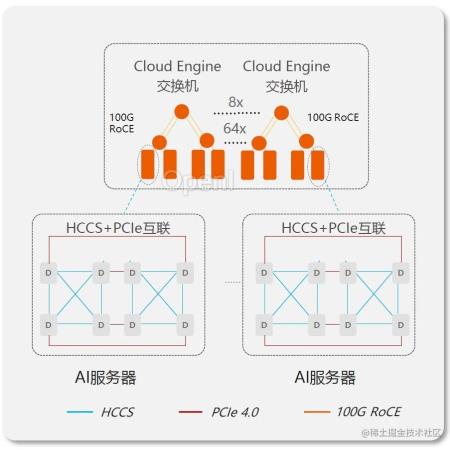
本文主要针对 MindSpore 和 Pytorch 分布式 AI 框架在进行多机多卡训练(双机16卡),为了文章具有更好的阅读体验,具体代码放置在GitHub:llm-action。
大模型国产化系列:
大模型国产化适配1-华为昇腾AI全栈软硬件平台总结
大模型国产化适配2-基于昇腾91
原文链接:大模型国产化适配4-基于昇腾910使用LLaMA-13B进行多机多卡训练
联系作者
文章来源:算法邦
作者微信:allplusai
作者简介:智猩猩矩阵账号之一,聚焦生成式AI,重点关注模型与应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。