AIGC动态欢迎阅读
原标题:超越CVPR 2024方法,DynRefer在区域级多模态识别任务上,多项SOTA
关键字:区域,视图,任务,分辨率,图像
文章来源:机器之心
内容字数:0字
内容摘要:
机器之心发布
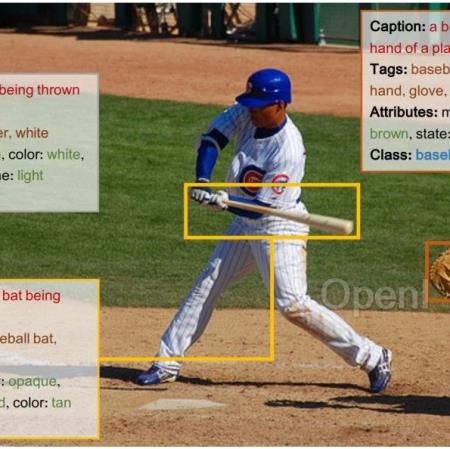
机器之心编辑部为了实现高精度的区域级多模态理解,本文提出了一种动态分辨率方案来模拟人类视觉认知系统。本文作者来自于中国科学院大学LAMP实验室,其中第一作者赵毓钟是中国科学院大学的2023级博士生,共同一作刘峰是中国科学院大学2020级直博生。他们的主要研究方向是视觉语言模型和视觉目标感知。
简介
DynRefer 通过模拟人类视觉认知过程,显著提升了区域级多模态识别能力。通过引入人眼的动态分辨率机制,DynRefer 能够以单个模型同时完成区域识别、区域属性检测和区域字幕生成(region-level captioning)任务,并在上述任务都取得 SOTA 性能。其中在 RefCOCOg 数据集的 region-level captioning 任务上取得了 115.7 CIDEr,显著高于 RegionGPT,GlaMM,Osprey,Alpha-CLIP 等 CVPR 2024 的方法。论文标题:DynRefer: Delving into Region-level Multi-modality Tasks via Dynamic Resolution
论文链接:
原文链接:超越CVPR 2024方法,DynRefer在区域级多模态识别任务上,多项SOTA
联系作者
文章来源:机器之心
作者微信:almosthuman2014
作者简介:专业的人工智能媒体和产业服务平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。