AIGC动态欢迎阅读
原标题:LLaMA 3 背后的大规模 GPU 集群 RoCE 网络建设
关键字:报告,流量,网络,通信,作者
文章来源:智猩猩AGI
内容字数:0字
内容摘要:
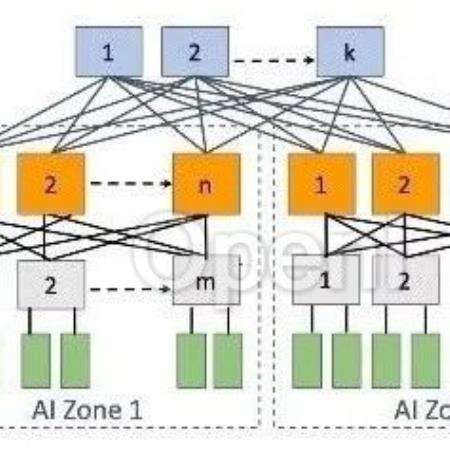
生成式AI时代最火AI芯片峰会下月来袭!9月6-7日,智猩猩发起主办的2024全球AI芯片峰会将在北京盛大举行。峰会设有开幕式、数据中心AI芯片专场、边缘/端侧AI芯片专场、智算集群技术论坛等7大板块。目前,来自AMD、高通、Habana、壁仞科技、摩尔线程、苹芯科技、亿铸科技、凌川科技、云天励飞、中国移动研究院、北极雄芯等40+企业的嘉宾已确认演讲或讨论。扫码申请免费票或购票参会~01背景模型越来越大,需要的 GPU 越来越多;与此同时 GPU 性能也在不断增强,配套的网络带宽也不断增加到 400G(Blackwell GPU 甚至需要到 800 Gbps)。Ranking 模型还在迁移到 GPU 的早期阶段,但使用 GPU 的规模也在不断增加;而 LLM 通常需要使用更大规模 GPU。在构建这种规模的网络的同时保持高性能 GPU 间通信很有挑战。
Meta 在其 LLaMA 3 技术报告中简单提到用于训练 LLaMA 3 的大规模 GPU 集群,不过在报告中并没有详细介绍其集群的构成以及相应的网络解决方案。Meta 最近发布了相应的 Paper,我们这里进行简单介绍。
对应的论文为
原文链接:LLaMA 3 背后的大规模 GPU 集群 RoCE 网络建设
联系作者
文章来源:智猩猩AGI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。