AIGC动态欢迎阅读
内容摘要:
生成式AI时代最火AI芯片峰会下月来袭!9月6-7日,智猩猩发起主办的2024全球AI芯片峰会将在北京盛大举行。峰会设有开幕式、数据中心AI芯片专场、边缘/端侧AI芯片专场、智算集群技术论坛等7大板块。目前,来自AMD、高通、Habana、壁仞科技、摩尔线程、苹芯科技、亿铸科技、凌川科技、云天励飞、中国移动研究院、北极雄芯等40+企业的嘉宾已确认演讲或讨论。扫名或购票~近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。模型压缩主要分为如下几类:
剪枝(Pruning)
知识蒸馏(Knowledge Distillation)
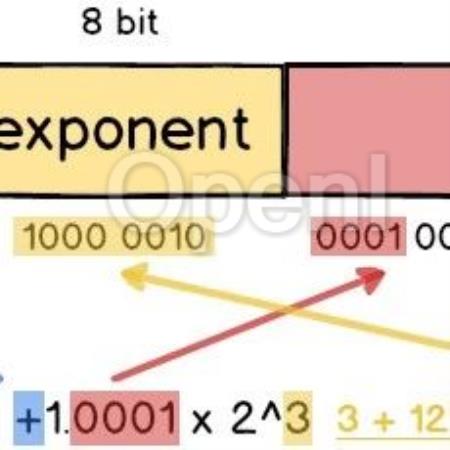
量化Quantization)本系列将针对一些常见大模型量化方案(GPTQ、LLM.int8()、SmoothQuant、AWQ等)进行讲述。
大模型量化概述
量化感知训练:
大模型量化感知训练技术原理:LLM-QAT
大模型量化感知微调技术原理:QLoRA
训练后量化:
大模型量化技术原理:GPTQ、LLM.in
原文链接:大模型量化技术原理:FP8
联系作者
文章来源:智猩猩AGI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。