AIGC动态欢迎阅读
原标题:一张图实现街道级定位,端到端图像地理定位大模型AddressCLIP登ECCV2024
关键字:图像,地址,数据,文本,模型
文章来源:量子位
内容字数:0字
内容摘要:
AddressCLIP项目组 投稿量子位 | 公众号 QbitAI拔草星人的好消息来啦!
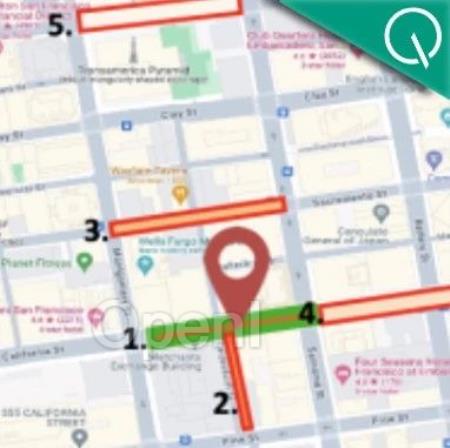
中科院自动化所和阿里云一起推出了街景定位大模型,只要一张照片就能实现街道级精度的定位。
有了模型的帮助,再也不用害怕遇到种草“谜语人”了。
比如给模型看一张旧金山的街景之后,它直接给出了具体的拍摄位置,并列举了附近的多个候选地址。
该模型名为AddressCLIP,基于CLIP构建。
相关论文AddressCLIP: Empowering Vision-Language Models for City-wide Image Address Localization已入选顶会ECCV2024。
传统的图像位置识别往往致力于以图像检索的方式来确定图像的GPS坐标,这种方法称为图像地理定位。
但GPS对于普通人来说晦涩难懂,并且图像检索需要建立并维护一个庞大的数据库,难以本地化部署。
本篇工作提出了更加用户友好的,端到端的图像地理定位任务。二者的对比示意图如下:
针对这个任务,为了实现上述效果,研究人员主要从数据集构建与定制化的模型训练两方面入手开展了研究。
图像地址定位数据集构建图像地址定位本质上是
原文链接:一张图实现街道级定位,端到端图像地理定位大模型AddressCLIP登ECCV2024
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。