AIGC动态欢迎阅读
原标题:北大对齐团队最新解读:OpenAI o1开启「后训练」时代强化学习新范式
关键字:模型,过程,能力,任务,数据
文章来源:智猩猩GenAI
内容字数:0字
内容摘要:
文章转载自公众号:机器之心,本文只做学术/技术分享,如有侵权,联系删文。
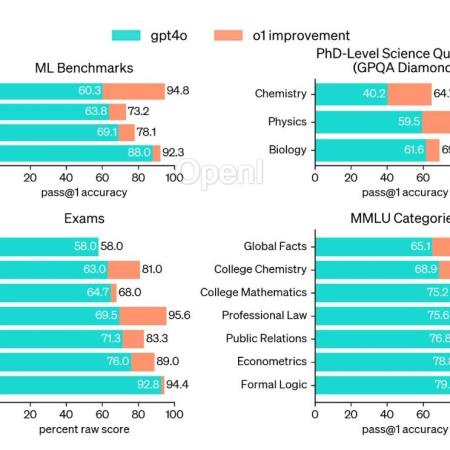
OpenAI o1 在数学、代码、长程规划等问题取得显著的进步。一部分业内人士分析其原因是由于构建足够庞大的逻辑数据集 ,再加上类似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足够的计算量用于搜索,总可以搜到最后的正确路径。然而,这样只是建立起问题和答案之间的更好的联系,如何泛化到更复杂的问题场景,技术远不止这么简单。AlphaGo 是强化学习在围棋领域中的一大成功,成功击败了当时的世界冠军。早在去年,Deepmind 的 CEO Demis Hassabis 便强调用 Tree Search 来增强模型的推理能力。根据相关人士推测,o1 的模型训练数据截止到去年十月份,而有关 Q * 的爆料大约是去年 11 月,这似乎展示 o1 的训练中也用到了 TreeSearch 的技巧。
实际上,OpenAI o1 运用的技术关键还是在于强化学习的搜索与学习机制,基于LLM 已有的推理能力,迭代式的 Bootstrap 模型产生合理推理过程(Rationales) 的能力,
原文链接:北大对齐团队最新解读:OpenAI o1开启「后训练」时代强化学习新范式
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。