AIGC动态欢迎阅读
原标题:图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)
关键字:梯度,通讯,数据,模型,参数
文章来源:智猩猩GenAI
内容字数:0字
内容摘要:
GTIC 2024中国AI PC创新峰会将于10月11日,在2024上海国际消费电子展TechG同期举办。联想集团首席研究员颜毅强、荣耀终端有限公司PC产品研发系统部部长席迎军等7位嘉宾,将分别围绕面向大模型的个人计算体系和交互、AI 重构PC、RISC-V AI芯片、AIGC在端侧产品的发展、操作系统与AI技术结合探索、联合模型和硬件的优化适配平台MLGuider、智能体个人助理等议题进行演讲,欢迎报名~在上一篇的介绍中,我们介绍了以Google GPipe为代表的流水线并行范式。当模型太大,一块GPU放不下时,流水线并行将模型的不同层放到不同的GPU上,通过切割mini-batch实现对训练数据的流水线处理,提升GPU计算通讯比。同时通过re-materialization机制降低显存消耗。
但在实际应用中,流水线并行并不特别流行,主要原因是模型能否均匀切割,影响了整体计算效率,这就需要算法工程师做手调。因此,今天我们来介绍一种应用最广泛,最易于理解的并行范式:数据并行。
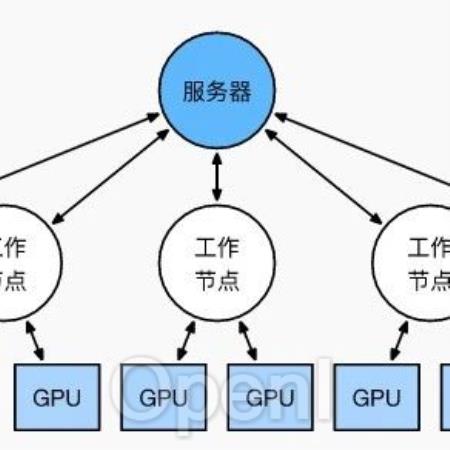
数据并行的核心思想是:在各个GPU上都拷贝一份完整模型,各自吃一份数据,算一份梯度,最后对梯度进行累加来更新整
原文链接:图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。