AIGC动态欢迎阅读
原标题:OCR-Omni来了,字节&华师统一多模态文字理解与生成 | NeurIPS2024
关键字:模型,视觉,字节跳动,文本,图像
文章来源:量子位
内容字数:0字
内容摘要:
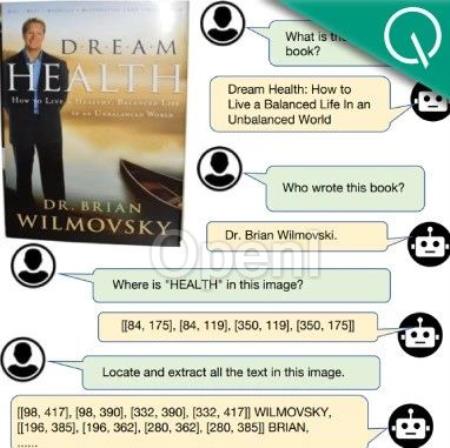
TextHarmony团队 投稿量子位 | 公众号 QbitAI多模态生成新突破,字节&华师团队打造TextHarmony,在单一模型架构中实现模态生成的统一,并入选NeurIPS 2024。
过去,视觉文字领域的大模型研究聚焦于单模态生成,虽然在个别任务上实现了模型的统一,但很难在OCR领域的多数任务上做到全面整合。
例如,Monkey等视觉语言模型(VLM)擅长文字检测、识别和视觉问答(VQA)等文本模态生成任务,却无法胜任文字图像的生成、抹除和编辑等图像模态生成任务。反之,以 AnyText 为代表的基于扩散模型的图像生成模型则专注于图像创建。因此,OCR领域亟需一个能够统一多模态生成的大模型。
为解决这一难题,字节跳动与华东师范大学的联合研究团队提出了创新性的多模态生成模型TextHarmony,不仅精通视觉文本的感知、理解和生成,还在单一模型架构中实现了视觉与语言模态生成的和谐统一。
目前论文已经上传arXiv,代码也即将开源,链接可在文末领取。
TextHarmony: 核心贡献TextHarmony的核心优势在于其成功整合了视觉文本的理解和生成能力。传统研究中,这两类任务
原文链接:OCR-Omni来了,字节&华师统一多模态文字理解与生成 | NeurIPS2024
联系作者
文章来源:量子位
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。