AIGC动态欢迎阅读
原标题:微软开源视觉GUI智能体:增强GPT-4V能力,超3800颗星
关键字:图标,模型,侵权,研究人员,能力
文章来源:智猩猩GenAI
内容字数:0字
内容摘要:
文章转载自公众号:AIGC开放社区,本文只做学术/技术分享,如有侵权,联系删文。
随着GPT-4V等多模态视觉大模型的出现,在理解和推理视觉内容方面获得了巨大进步。但是将预测的动作准确转换为UI上的实际操作时却很难。
例如,难以准确识别用户界面内可交互的图标,以及在理解屏幕截图中各种元素的语义并将预期动作与屏幕上相应区域的关联。
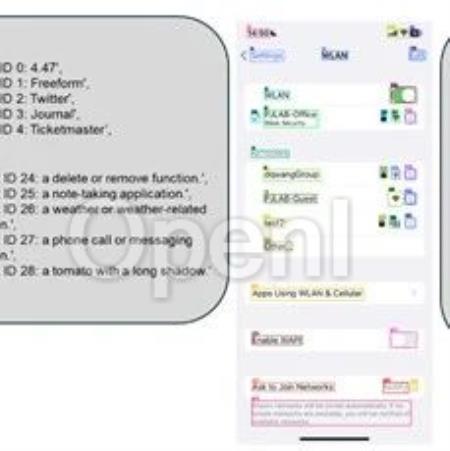
为了解决这个难题,微软研究人员开源了纯视觉GUI智能体OmniParser,能够轻松将用户界面截图解析为结构化元素,显著增强GPT-4V等模型对应界面区域预测的能力。目前,OmniParser在Github上非常火,已经超过3800颗星。开源地址:https://github.com/microsoft/OmniParserOmniParser功能展示
通常在UI识别操作任务中,模型需要具备两个关键能力:一是理解当前UI屏幕的内容,包括分析整体布局以及识别带有数字 ID 标注的图标的功能;二是基于当前屏幕状态预测下一步有助于完成任务的动作。
研究人员发现,将这两个任务整合在一个模型中执行会给模型带来较大负担,影响其性能表现。因此,OmniParser 采用了一
原文链接:微软开源视觉GUI智能体:增强GPT-4V能力,超3800颗星
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。