EMMA是Waymo推出的一款先进的端到端自动驾驶多模态模型,基于Gemini模型开发。该系统能够将原始相机传感器数据直接转换为驾驶相关的输出,如路径规划、对象识别和道路元素图。EMMA还将非传感器输入和输出转化为自然语言文本,借助预训练的巨大语言模型积累的世界知识,在统一的语言空间中高效地处理多种驾驶任务。
EMMA是什么
EMMA是Waymo基于Gemini模型推出的端到端自动驾驶多模态模型,能够将原始相机传感器数据直接映射为特定于驾驶的输出,包括规划轨迹、感知周围对象和构建道路图元素。该模型通过将非传感器输入和输出以自然语言文本的形式呈现,运用预训练的大型语言模型的丰富知识,在一个统一的语言空间内协同处理多种驾驶任务。EMMA在nuScenes规划和Waymo开放数据集上表现出色,但其也存在一些限制,例如对图像帧处理数量的限制、缺乏精确的3D传感器集成以及较高的计算成本。此模型旨在推动自动驾驶模型架构的进步,提升系统在复杂场景中的泛化与推理能力。
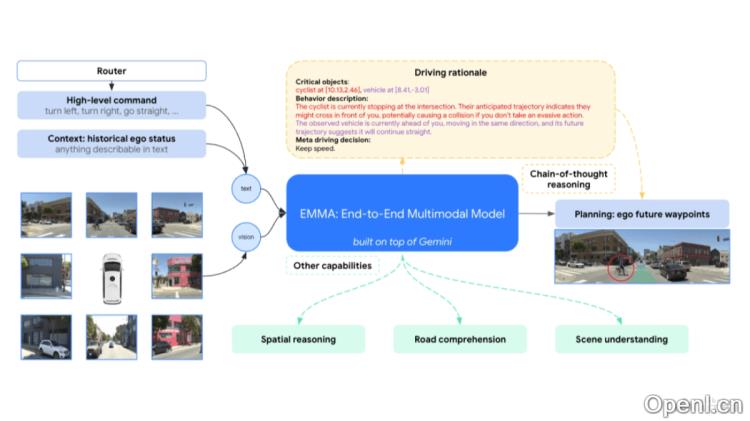
EMMA的主要功能
- 端到端规划:
- 从原始相机传感器数据直接生成自动驾驶车辆的未来轨迹。
- 将轨迹转化为车辆控制动作,例如加速和转向。
- 3D对象检测:以摄像头为主要传感器,检测和识别周围的物体,包括车辆、行人和骑行者。
- 道路图元素识别:识别和构建道路图,包括车道线、交通标志等关键道路元素。
- 场景理解:理解整体场景的上下文,包括临时道路阻塞及其他影响驾驶的因素。
- 多任务处理:在统一的语言空间中协同处理多种驾驶任务,通过任务特定的提示生成输出。
- 链式思维推理:通过链式思维推理增强模型的决策能力和可解释性,使其在预测未来轨迹时能够阐明决策依据。
EMMA的技术原理
- 多模态大型语言模型(MLLMs):基于预训练的MLLMs,如Gemini,该模型在广泛的互联网数据上训练,具备丰富的“世界知识”。
- 自然语言表示:所有非传感器输入和输出(如导航指令、车辆状态、轨迹和3D位置)以自然语言文本形式表示。
- 视觉问题回答(VQA):将驾驶任务重新构想为VQA问题,利用Gemini的预训练能力,保留广泛的世界知识。
- 自回归模型:采用自回归Gemini模型处理交错的文本和视觉输入,生成文本输出。
- 端到端训练:通过端到端训练,从传感器数据直接生成驾驶动作,避免模块间的符号化接口需求。
EMMA的项目地址
- arXiv技术论文:https://arxiv.org/pdf/2410.23262
EMMA的应用场景
- 城市与郊区驾驶:EMMA能够处理复杂的城市交通环境及郊区道路条件,提供实时的驾驶决策和轨迹规划。
- 交通拥堵与复杂交叉口:在交通拥堵或复杂交叉口场景中,EMMA能够进行有效的路径规划和决策,确保安全高效的导航。
- 特殊天气与光照条件:EMMA适应多种天气与光照条件,如雨、雾或夜间驾驶,保持稳定的驾驶性能。
- 施工区域与临时道路封闭:基于其场景理解能力,EMMA能够识别施工区域和临时道路封闭情况,并做出相应的驾驶调整。
- 紧急情况响应:在遇到紧急情况时,如突然出现的障碍物或动物,EMMA能够迅速反应,采取避让或减速的措施。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。