OpenR是一个由伦敦大学学院(UCL)、上海交通大学、利物浦大学、香港科技大学(广州)和西湖大学共同开发的开源训练框架,旨在提升大型语言模型(LLM)在复杂推理方面的能力。它将过程奖励模型(PRM)训练、强化学习和多种搜索策略巧妙整合,超越了传统自回归模型的方法。
OpenR是什么
OpenR是一个创新的开源框架,旨在提升大型语言模型(LLM)的推理能力。该框架结合了搜索、强化学习和过程监督的技术,极大地改善了模型在推理过程中的表现。受OpenAI o1模型的启发,OpenR通过整合强化学习来显著增强模型的推理能力。它是第一个提供集成技术开源实现的平台,支持LLM在有效的数据获取、训练和推理路径上实现复杂的推理能力。OpenR具备在线强化学习训练的功能,并支持多种搜索策略,遵循测试时扩展法则,使模型能够在测试时生成或搜索以提供更精细的输出。此外,OpenR还提供了一条自动化的数据管道,从结果标签中提取推理步骤,降低人工标注的工作量,同时确保有价值的推理信息的收集。
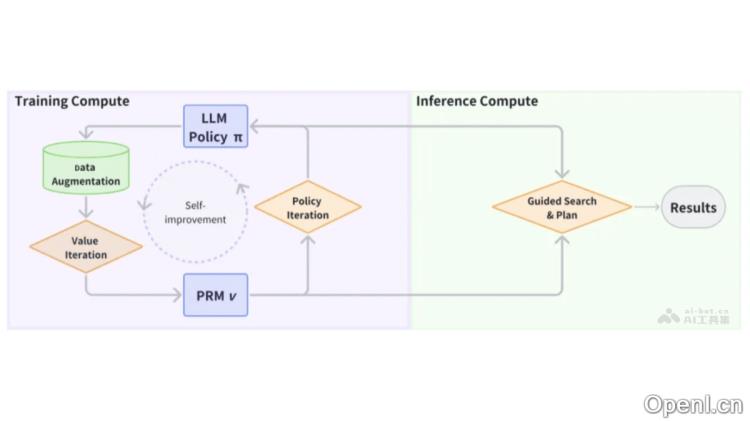
OpenR的主要功能
- 集成训练与推理:将数据获取、强化学习训练(包括在线和离线)及非自回归解码整合在一个统一的平台上。
- 过程奖励模型(PRM):在训练阶段利用策略优化技术改进LLM策略,并在解码阶段引导LLM的搜索过程。
- 强化学习环境:将数学问题建模为马尔可夫决策过程(MDP),通过强化学习方法优化模型策略。
- 多策略搜索与解码:支持多种搜索算法,如Beam Search和Best-of-N,结合PRM进行的引导搜索和评分。
- 数据增强与自动化标注:通过自动化生成合成样本,减少对人工标注的依赖,提高数据收集效率。
OpenR的技术原理
- 过程奖励模型(PRM):PRM用于评估解决方案步骤的准确性,通过监督学习训练,将正确与错误的判定作为分类标签,预测每一步的后续标记。
- 策略迭代:在训练过程中,PRM通过策略优化技术如策略迭代改进LLM策略,在解码阶段引导LLM的搜索过程,推动推理朝向更有效的结果发展。
- 马尔可夫决策过程(MDP):将数学问题转化为MDP,由状态、动作和奖励组成,模型通过生成推理步骤作为动作,根据当前状态和动作决定下一个状态。
- 强化学习:通过近端策略优化(PPO)和群体相对策略优化(GRPO)等算法进行在线强化学习训练,优化模型生成的语言输出。
- 搜索算法:在解码阶段,使用PRM评估每个解决步骤的准确性,结合语言模型进行引导搜索和多次生成的评分或投票。
OpenR的项目地址
- 项目官网:openreasoner.github.io
- GitHub仓库:https://github.com/openreasoner/openr
- 技术论文:https://github.com/openreasoner/openr/blob/main/reports/OpenR-Wang.pdf
OpenR的应用场景
- 数学问题求解:OpenR能够解决数学问题,通过生成和评估推理步骤,找到正确的解答路径。
- 代码生成与调试:在软件开发过程中,OpenR可帮助生成代码片段,或在调试阶段寻找和修正代码中的错误。
- 自然语言处理(NLP)任务:OpenR适用于机器阅读理解、问答系统、文本摘要等需要深入理解文本和逻辑推理的NLP任务。
- 教育辅助:在教育领域,OpenR可作为辅助工具,帮助学生理解复杂的概念和解题步骤,提供个性化的学习路径。
- 自动化客户服务:在客户服务领域,OpenR能够基于推理用户的问题和需求,提供准确的答案和解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。