PoseTalk 是一款开源项目,专注于基于文本和音频的姿势控制及细化方法,旨在一次性生成能够说话的头部视频。它能够通过图像、驱动音频和姿势合成生成真实的说话人脸视频,为用户提供高效、便捷的头部动画生成方案。
PoseTalk是什么
PoseTalk 是一个创新的开源项目,利用文本提示和音频输入,生成自然的头部视频。它通过将图像与驱动音频和姿势结合,合成出逼真的说话人脸动画。PoseTalk 的核心技术在于使用姿势潜在空间生成潜在,确保头部效果自然且真实。该项目采用 Pose Latent Diffusion (PLD) 模型及级联网络 CoarseNet 和 RefineNet,能够实现高质量的唇部同步和姿势生成,适用于虚拟主播、在线教育及社交媒体等多种应用场景。
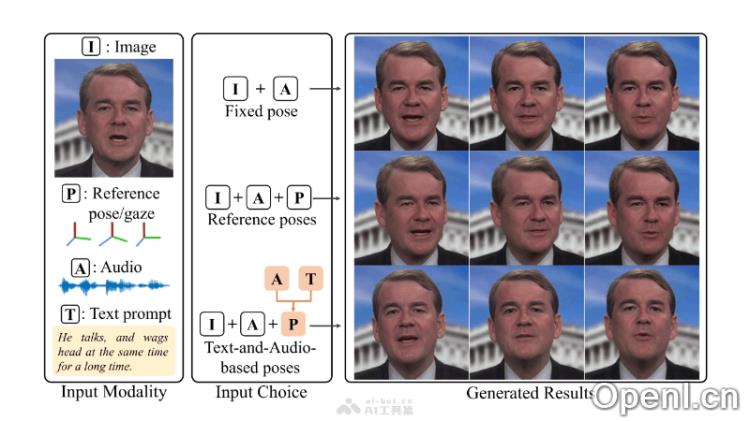
PoseTalk的主要功能
- 文本与音频驱动的姿势生成:PoseTalk 根据用户的文本提示和音频输入,生成反映长期语义和短期变化的头部姿势。
- 姿势潜在扩散模型(PLD):通过在姿势潜在空间中生成潜在,使得头部显得更加自然和真实。
- 级联网络细化策略:结合 CoarseNet 和 RefineNet 两个网络,先生成粗略的动画,再细化唇部,以提升唇部同步效果。
- 高质量的唇部同步:PoseTalk 生成的头部动画与音频高度一致,尤其在口型同步方面表现优异。
- 多样化的姿势生成:用户可以通过不同的文本提示指导 PoseTalk 生成多种姿势,增强动画的多样性和个性化。
PoseTalk的技术原理
- Pose Latent Diffusion (PLD) 模型:该模型在神经参数化头部模型的表达空间中运作,捕捉到人头的细致特征。PLD 模型能够将文本与音频信息转化为头部的姿势和,为后续动画生成打下基础。
- 级联网络细化策略:PoseTalk 利用 CoarseNet 和 RefineNet 进行自然说话视频的合成。CoarseNet 负责生成粗略,RefineNet 则通过逐步提高分辨率来细化唇部,从而学习更精确的唇部动作,提升同步性能。
- 音频特征提取:PoseTalk 基于预先训练的音频编码器(如Wave2Vec 2.0)从输入音频中提取特征。这些音频特征与文本信息结合,共同驱动头部模型的,确保生成的动画与音频完美契合,包括口型和表情等方面。
- 训练与推理:在训练阶段,PoseTalk 使用变分自编码器(VAE)学习头部姿势和眼动的低维潜在空间。推理阶段,PLD 预测自然的姿势序列,并通过视频生成模型将音频特征与生成的姿势序列结合,从而合成真实的说话视频。
PoseTalk的项目地址
- 项目官网:posetalk.github.io/
- arXiv技术论文:https://arxiv.org/pdf/2409.02657
PoseTalk的应用场景
- 虚拟助手和数字人:PoseTalk 可用于生成虚拟助手或数字人的生动头部动画,提供更自然和吸引人的互动体验。
- 电影和游戏制作:在娱乐行业,PoseTalk 帮助生成高质量角色动画,使角色的头部动作和表情更真实,增强观众的沉浸感。
- 在线教育与培训:在远程教学中,PoseTalk 可生成教师或讲师的动态头像,提供更生动的教学体验。
- 社交媒体与内容创作:用户可以通过 PoseTalk 创建个性化的动态头像或表情包,增加社交媒体内容的互动性和趣味性。
常见问题
- PoseTalk 是否免费使用?:是的,PoseTalk 是一个开源项目,任何人都可以免费使用和修改。
- 我如何获取 PoseTalk 的源代码?:您可以访问 PoseTalk 的官方网站获取源代码及相关文档。
- PoseTalk 支持哪些语言的文本输入?:PoseTalk 设计上支持多种语言的文本输入,以适应不同用户的需求。
- 如何确保生成的动画与音频同步?:PoseTalk 的设计中包含高质量的唇部同步策略,确保生成的动画与音频高度一致。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。