MagicMan 是一项由清华大学深圳国际研究生院、腾讯AI实验室、香港科技大学、斯坦福大学和香港中文大学的研究团队共同研发的人工智能项目,旨在通过深度学习技术从单张2D图像生成高质量的3D人类模型。该项目结合了预训练的2D扩散模型和参数化的SMPL-X模型,利用混合多视角注意力机制和迭代细化策略,能够实现精准的3D感知和图像生成,广泛应用于游戏、电影、虚拟现实等多个领域。
MagicMan是什么
MagicMan 是一个前沿的AI项目,专注于从单一的2D图像生成精细的3D人类模型。通过结合深度学习技术和先进的3D建模方法,MagicMan 不仅能生成高质量的人物模型,还能在不同视角下提供全方位的视觉呈现。它在游戏设计、影视制作和虚拟现实等行业展现出了巨大的应用潜力。
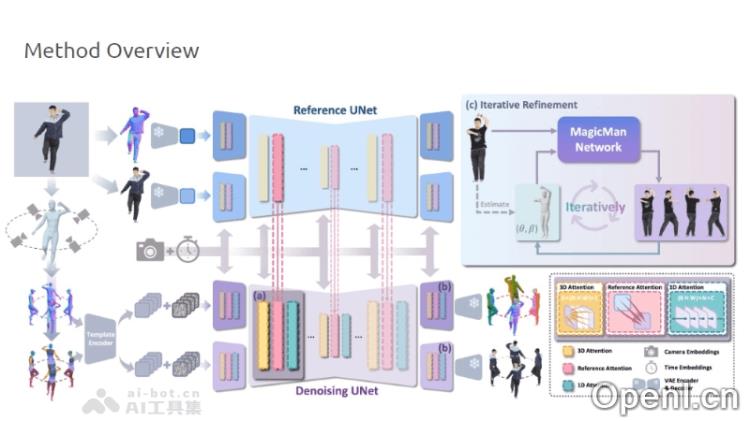
主要功能
- 单图像生成3D模型:能够从一张2D人物图像生成高质量的3D人类模型,极大地简化了建模流程。
- 多视角图像合成:生成不同视角下的人物图像,增强视觉效果的一致性。
- 法线图生成:同时提供与RGB图像相匹配的法线图,提升3D模型的真实感和细腻度。
- 3D感知能力:依托SMPL-X模型,MagicMan能够精确理解和生成具有复杂3D结构的人物模型。
- 混合多视角注意力机制:确保从不同视角生成的图像在视觉上保持连贯性和一致性。
技术原理
- 预训练的2D扩散模型:通过大量图像数据的预训练,学习丰富的纹理和外观特征。
- 参数化的SMPL-X模型:这一模型能够精确描述人体的几何结构及其姿态变化。
- 混合多视角注意力机制:结合1D和3D注意力机制,实现不同视角间信息的有效交互,确保视觉上的一致性。
- 几何感知的双分支生成:同时生成RGB图像和法线图像,利用几何信息提升图像的几何一致性,使得生成的3D图像在视觉和结构上都极为逼真。
项目地址
- 项目官网:thuhcsi.github.io/MagicMan
- GitHub仓库:https://github.com/thuhcsi/MagicMan
- arXiv技术论文:https://arxiv.org/pdf/2408.14211
应用场景
- 游戏开发:在游戏设计中,MagicMan 可快速生成逼真的角色和动态环境,提升角色设计的多样性和真实感。
- 电影与动画制作:电影行业利用MagicMan从2D图像或真实演员照片生成3D角色模型,便于动作捕捉或直接用于动画制作,节省建模时间和成本。
- 虚拟现实(VR)与增强现实(AR):在VR和AR应用中,MagicMan能够创造出逼真的虚拟角色和环境,增强用户的沉浸体验和交互感。
- 时尚与零售:时尚行业运用MagicMan技术建立虚拟试衣间,消费者可上传自己的图像,预览不同服装的穿着效果,提升购物体验的个性化。
- 教育与训练模拟:在教育领域,MagicMan用于生成多样的角色和场景,进行模拟训练,如医学模拟和历史重现,从而提高学习效果和训练质量。
常见问题
如果您对MagicMan有任何疑问,欢迎访问我们的官网或GitHub页面,获取更多信息和支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。