mPLUG-Owl3是阿里巴巴最新推出的一款通用多模态人工智能模型,专门设计用于理解和处理多张图片以及长时间视频。其推理效率显著提升,能够在仅仅4秒内完成对2小时电影的分析,同时确保了内容理解的高准确性。
mPLUG-Owl3是什么
mPLUG-Owl3是阿里巴巴开发的一款先进的多模态AI模型,旨在深度理解多图及长视频内容。该模型通过创新的Hyper Attention模块,增强了视觉与语言信息的融合能力,支持复杂的多图场景和长视频分析。mPLUG-Owl3在多个评测基准中取得了行业领先的成绩,其相关论文、代码和资源已全面开源,供研究人员和开发者使用。
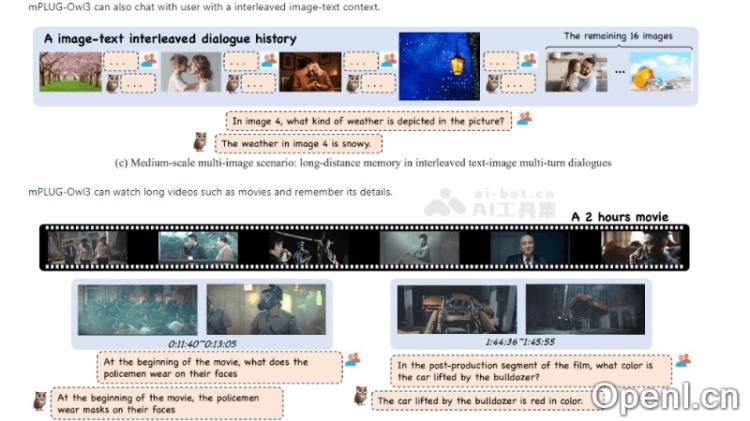
mPLUG-Owl3的主要功能
- 多图与长视频理解:快速处理和分析多张图像及长时间的视频内容。
- 高效推理:在极短的时间内完成对大量视觉信息的分析,比如在4秒内处理2小时的电影。
- 保持高准确性:在提升效率的同时,确保对内容的理解不受影响。
- 多模态信息融合:通过Hyper Attention模块,有效整合视觉与语言信息。
- 跨模态对齐:模型训练包括跨模态对齐,增强对图文信息的理解和交互能力。
mPLUG-Owl3的技术原理
- 多模态融合:模型将视觉信息(如图片)与语言信息(如文本)融合,以实现对多图和视频内容的理解,利用自注意力和跨模态注意力机制进行处理。
- Hyper Attention模块:这一创新模块高效整合视觉和语言特征,通过共享LayerNorm、模态专属的Key-Value映射和自适应门控设计,优化信息的并行处理。
- 视觉编码器:采用如SigLIP-400M的视觉编码器提取图像特征,并通过线性层映射到与语言模型相同的维度,以便实现有效的特征融合。
- 语言模型:使用例如Qwen2的语言模型处理和理解文本信息,并通过融合视觉特征增强语言表示能力。
- 位置编码:引入多模态交错的旋转位置编码(MI-Rope),保留图文的位置信息,确保模型能够理解图像和文本在序列中的相对位置。
mPLUG-Owl3的项目地址
- GitHub仓库:https://github.com/X-PLUG/mPLUG-Owl/
- HuggingFace链接:https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
- arXiv技术论文:https://arxiv.org/pdf/2408.04840
如何使用mPLUG-Owl3
- 环境准备:确保计算环境中安装必要的软件和库,例如Python、PyTorch或其他深度学习框架。
- 获取模型:从GitHub或Hugging Face下载mPLUG-Owl3模型的预训练权重和配置文件。
- 安装依赖:根据模型文档说明,安装所需的依赖库,可能包括特定的深度学习库和数据处理库。
- 数据准备:准备待处理的数据,如图片、视频或图文对,确保数据格式符合模型的输入要求。
- 模型加载:使用合适的深度学习框架加载预训练的mPLUG-Owl3模型。
- 数据处理:对数据进行预处理,以适应模型输入格式,包括图像大小调整、归一化等步骤。
- 模型推理:使用模型对数据进行推理,模型将输出对内容的理解与分析结果。
mPLUG-Owl3的应用场景
- 多模态检索增强:准确理解多模态知识,支持问题解答,并能指出判断依据。
- 多图推理:理解不同材料之间的关系,进行有效推理,例如判断不同图片中动物的生存环境。
- 长视频理解:在短时间内处理并理解长视频内容,能迅速回答有关视频不同片段的问题。
- 多图长序列理解:在多模态多轮对话和长视频理解等场景中展示高效的理解与推理能力。
- 超长多图序列评估:在面对超长图像序列和干扰图像时,保持高鲁棒性,即使输入数百张图像仍能维持高性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。