MDT-A2G是由复旦大学与腾讯优图携手打造的先进AI模型,旨在根据语音内容实时生成相应的手势动作。该模型通过模拟人类在交流中自然而然产生的手势,使计算机的表达更加生动和自然。
MDT-A2G是什么
MDT-A2G是复旦大学与腾讯优图联合开发的人工智能模型,专门设计用于根据语音内容同步生成相应的手势动作。该模型通过模仿人类在交流过程中自然产生的手势,使计算机的“表演”更加生动和自然。MDT-A2G综合分析语音、文本、情感等多种信息,运用去噪和加速采样等技术,生成连贯且逼真的手势序列。
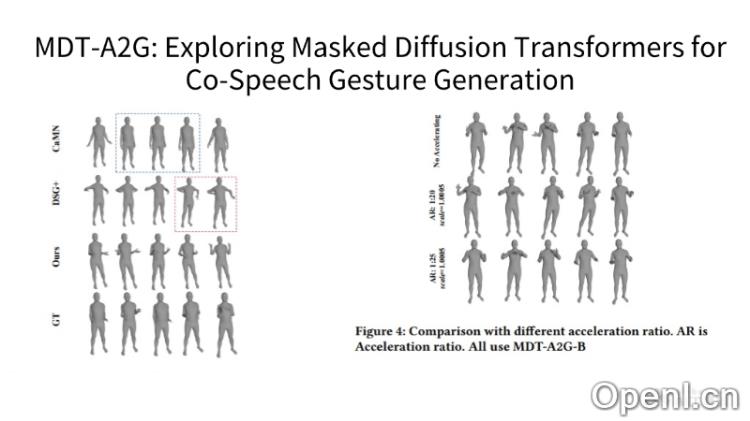
MDT-A2G的主要功能
- 多模态信息融合:整合语音、文本、情感等多种信息源,进行综合分析,从而生成与语音同步的手势。
- 去噪处理:依靠去噪技术,修正和优化手势动作,确保生成的手势既准确又自然。
- 加速采样:采用高效的推理策略,利用之前计算的结果来减少后续的去噪计算量,实现快速生成。
- 时间对齐的上下文推理:强化手势序列之间的时间关系学习,生成连贯且逼真的动作。
MDT-A2G的技术原理
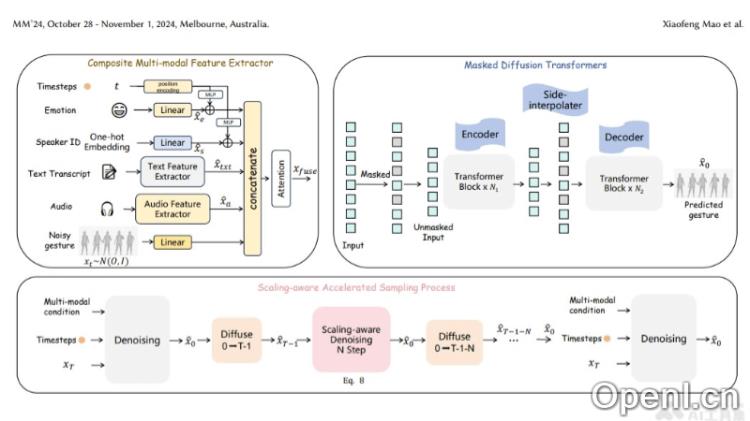
- 多模态特征提取:该模型从语音、文本、情感等多种信息源中提取特征,涉及语音识别技术将语音转换为文本,以及情感分析来识别说话者的情绪状态。
- 掩蔽扩散变换器:MDT-A2G采用创新的掩蔽扩散变换器结构,通过在数据中引入随机性并逐步去除这些随机性来生成目标输出,类似于去噪过程。
- 时间对齐和上下文推理:模型理解语音与手势之间的时间关系,确保手势与语音同步,涉及序列模型,能够处理时间序列数据并学习时间依赖性。
- 加速采样过程:为了提升生成效率,MDT-A2G引入了一种缩放感知的加速采样过程,利用先前计算的结果减少后续计算量,从而加快手势生成速度。
- 特征融合策略:模型采用创新的特征融合策略,将时间嵌入与情感和身份特征结合,并与文本、音频和手势特征相融合,形成全面的特征表示。
- 去噪过程:在生成手势时,模型逐步去除噪声,并优化手势动作,确保生成的手势既准确又自然。
MDT-A2G的项目地址
- GitHub仓库:https://github.com/sail-sg/MDT
- Hugging Face模型库:https://huggingface.co/spaces/shgao/MDT
- arXiv技术论文:https://arxiv.org/pdf/2408.03312
MDT-A2G的应用场景
- 增强交互体验:虚拟助手可利用MDT-A2G模型生成的手势,提升与用户的非语言交流,使对话更加自然和人性化。
- 教育和培训:虚拟教师或培训助手可以通过手势辅助教学,提升学习效率和参与度。
- 客户服务:在客户服务场景中,虚拟客服助手通过手势更清晰地传达信息,从而提高服务质量和用户满意度。
- 辅助残障人士:对于听力或语言障碍人士,虚拟助手能够通过手势提供更易理解的交流方式。
常见问题
- MDT-A2G的主要优势是什么? 该模型通过多模态信息融合与高效的生成策略,能够生成自然流畅的手势,提高人机交互的质量。
- 如何获取MDT-A2G? 用户可通过GitHub和Hugging Face等平台访问相关代码和模型。
- MDT-A2G的适用范围是什么? 该模型可广泛应用于虚拟助手、教育培训、客户服务以及辅助残障人士等多个场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。