MinerU是什么
MinerU是由上海人工智能实验室OpenDataLab团队开发的一款开源智能数据提取工具,专注于高效解析和提取复杂的PDF文档。该工具可以将包含图像、公式、表格等多种元素的多模态PDF文档转换为易于分析的Markdown格式,同时支持从网页和电子书中提取内容,显著提升AI语料的准备效率。MinerU配备高精度的PDF解析工具链,能够自动识别乱码,保持文档结构,并将公式转换为LaTeX格式,广泛应用于学术、财务、法律等多个领域,支持在CPU和GPU上运行,兼容Windows、Linux和Mac平台,性能卓越。
MinerU的主要功能
- PDF到Markdown转换:将多种内容类型的PDF文档转换为结构化的Markdown格式,便于后续的编辑和分析。
- 多模态内容处理:具备识别和处理PDF中的图像、公式、表格和文本等多种内容的能力。
- 结构和格式保留:在转换过程中,保留原始文档的结构和格式,包括标题、段落和列表等。
- 公式识别与转换:专门针对数学公式,能够识别并转换为LaTeX格式,便于学术交流和技术文档的使用。
- 去除干扰元素:自动删除页眉、页脚、脚注和页码等无关信息,净化文档内容。
- 乱码识别与处理:自动检测并纠正PDF文档中的乱码,提高信息提取的准确性。
- 高质量解析工具链:集成了先进的PDF解析工具,包括布局检测、公式检测和光学字符识别(OCR),确保提取结果的高准确度。
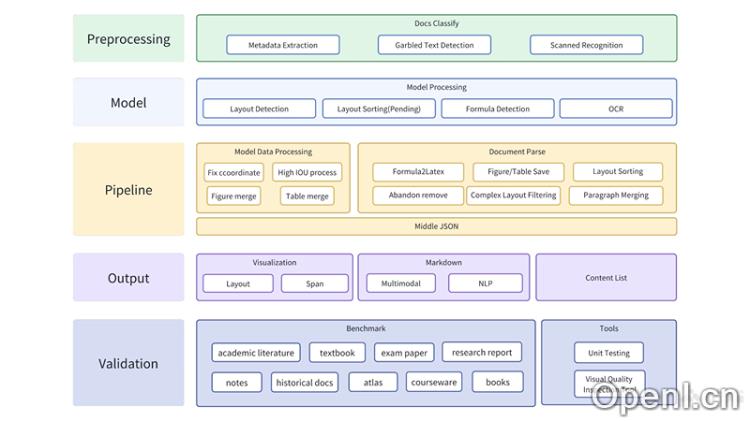
MinerU的技术原理
- PDF文档分类预处理:在处理PDF文档之前,MinerU首先对文档进行分类,识别其类型(如文本型、图层型或扫描版PDF),并进行相应的预处理,如检测乱码和识别扫描文档。
- 模型解析与内容提取:
- 布局检测:采用基于深度学习的模型,如LayoutLMv3,进行区域检测,识别文档中的图像、表格、标题和文本等不同区域。
- 公式检测:利用自研的YOLOv8模型识别文档中的数学公式,区分行内和行间公式。
- 公式识别:通过UniMERNet模型解析数学公式,并将其转换成LaTeX格式。
- 光学字符识别(OCR):使用PaddleOCR等OCR技术识别文档中的文本内容。
- 管线处理:将模型解析得到的数据输入处理管线,进行后处理,包括:
- 确定块级别的顺序。
- 删除无用元素。
- 依据版面对内容进行排序和拼装,以确保正文的连贯性。
- 进行坐标修复、高iou处理、图片和表格描述合并、公式替换、图标转储、Layout排序等操作。
- 多种格式输出:处理后的文档信息可以转换为统一的中间态格式(middle-json),并根据需求输出为不同的格式,如Layout、Span、Markdown或Content list等。
- PDF提取结果质检:通过人工标注的PDF自测评测集对整个流程进行检测,确保提取效果的优化。使用可视化质检工具进行人工质检与标注,反馈给模型训练,进一步提升模型能力。
MinerU的项目地址
- 项目官网:https://opendatalab.com/OpenSourceTools/Extractor/PDF
- GitHub仓库:https://github.com/opendatalab/PDF-Extract-Kit
- HuggingFace模型库:https://huggingface.co/wanderkid/PDF-Extract-Kit
- 魔搭社区模型库:https://www.modelscope.cn/models/wanderkid/PDF-Extract-Kit
MinerU的应用场景
- 学术研究:研究人员能够从学术论文和期刊中提取关键信息,包括文本、公式和图表,为文献综述和数据分析提供支持。
- 法律文档处理:法律专业人士可以使用MinerU从合同、法律意见书及其他法律文件中提取条款和证据,从而提升工作效率。
- 技术文档管理:工程师和技术作者可从技术手册和产品文档中提取技术规格和操作步骤,便于知识管理和技术传播。
- 知识管理和信息检索:企业和组织可以利用MinerU从内部文档库中提取信息,构建知识库,提升信息检索效率。
- 数据挖掘和自然语言处理(NLP):数据科学家和NLP研究人员能够使用MinerU提取的数据来训练和优化机器学习模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。