AniPortrait是一款由腾讯开源的照片对口型视频生成框架,能够通过音频和一张参考肖像图像生成高质量的动画,类似于阿里推出的EMO。该框架的工作流程分为两个主要阶段:首先,从音频中提取3D面部特征并转换为2D面部标记点;然后,运用扩散模型和模块,将这些标记点转化为连贯且逼真的动画。AniPortrait的生成动画具有自然性和多样性,并提供了灵活的面部动作编辑和再现功能。
AniPortrait是什么
AniPortrait是腾讯开源的一款创新性框架,旨在通过音频和参考图像生成高质量的口型动画。该框架主要由两个模块构成,分别是Audio2Lmk和Lmk2Video,能够有效提取和转换面部特征,生成视觉上真实的动态效果。

AniPortrait的官网入口
- GitHub代码库:https://github.com/Zejun-Yang/AniPortrait
- arXiv研究论文:https://arxiv.org/abs/2403.17694
- Hugging Face模型:https://huggingface.co/ZJYang/AniPortrait/tree/main
- Hugging Face Demo:https://huggingface.co/spaces/ZJYang/AniPortrait_official
AniPortrait的主要功能
- 音频驱动的动画生成:通过输入音频文件,AniPortrait能够自动生成与之同步的面部动画,包括嘴唇、面部表情及头部姿势。
- 高质量的视觉效果:利用先进的扩散模型和模块,AniPortrait能够生成高分辨率且视觉上逼真的肖像动画,提供卓越的视觉体验。
- 时间一致性:该框架确保生成的动画在时间上流畅连贯,避免出现突兀的跳跃或不一致现象。
- 灵活性和可控性:通过3D面部表示作为中间特征,AniPortrait允许用户对生成的动画进行定制和调整,增强了编辑的灵活性。
- 面部表情和嘴唇动作的精确捕捉:AniPortrait通过改进的PoseGuider模块和多尺度策略,能够精准捕捉和再现嘴唇的细微动作及复杂表情。
- 与参考图像的一致性:框架整合参考图像的外观信息,确保生成的动画视觉上与原始肖像保持一致,避免身份不匹配的问题。
AniPortrait的工作机制
AniPortrait由两个核心模块构成:Audio2Lmk和Lmk2Video。
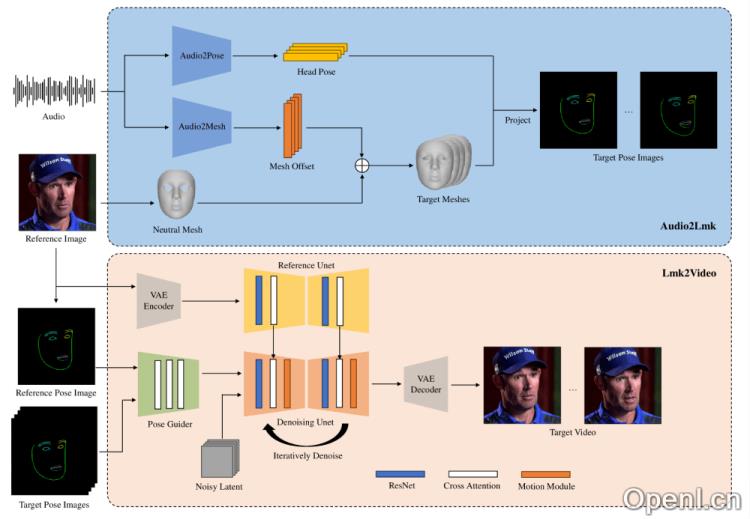
1. Audio2Lmk模块(音频到2D面部标记点)
Audio2Lmk模块旨在从音频输入中提取一系列面部表情和嘴唇动作的3D面部网格及头部姿势信息。该模块使用预训练的wav2vec模型提取音频特征,准确识别音频中的发音与语调,从而为生成真实的面部动画奠定基础。随后,利用音频特征通过全连接层转换为3D面部网格,并使用变压器解码器解码姿势序列,最终通过透视投影将信息转换为2D面部标记点序列。
2. Lmk2Video模块(2D面部标记点到视频)
Lmk2Video模块负责根据参考肖像图像和面部标记点生成高质量的肖像视频。该模块借鉴AnimateAnyone的网络架构,结合Stable Diffusion 1.5作为骨干,并通过时间模块将多帧噪声输入转换为视频帧。还引入ReferenceNet用于提取参考图像的外观信息,确保视频中的面部身份一致性。同时,增强的PoseGuider模块采用ControlNet的多尺度策略,促进参考标记点与目标标记点之间的交互,提高了嘴唇动作的捕捉精度。
应用场景
AniPortrait可以广泛应用于多个领域,如影视制作、游戏开发、虚拟现实、社交媒体内容创作等,为用户提供了一种新颖的表达方式和互动体验。
常见问题
1. AniPortrait可以用于哪些类型的音频?
AniPortrait支持多种音频格式,包括音乐、对话和配音等,只要音频中包含清晰的语音信息即可。
2. 是否可以自定义生成的动画?
是的,AniPortrait提供灵活的编辑选项,允许用户对生成的动画进行定制和调整。
3. 生成的动画兼容哪些平台?
AniPortrait生成的动画可以在各类支持视频播放的平台上使用,包括社交媒体、网站和应用程序等。
相关文章

全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。