ELLA(高效的大模型适配器)是一项由腾讯研究团队开发的创新技术,旨在显著提升文本到图像生成模型在处理复杂文本提示时的语义对齐能力。通过引入时序感知语义连接器(TSC),ELLA能够动态提取预训练大型语言模型(LLM)中的时序依赖性,从而更精准地理解和生成与文本提示相符的图像。
ELLA是什么
ELLA(Efficient Large Language Model Adapter)是一种先进的方法,专为提升文本到图像生成模型在解析复杂文本提示时的语义一致性而设计。传统的扩散模型往往依赖于CLIP作为文本编码器,但在处理包含多个对象、详细属性和复杂关系的长文本时,效果有限。为此,研究团队提出了ELLA,通过时序感知语义连接器(TSC),增强了模型对复杂提示的理解能力。
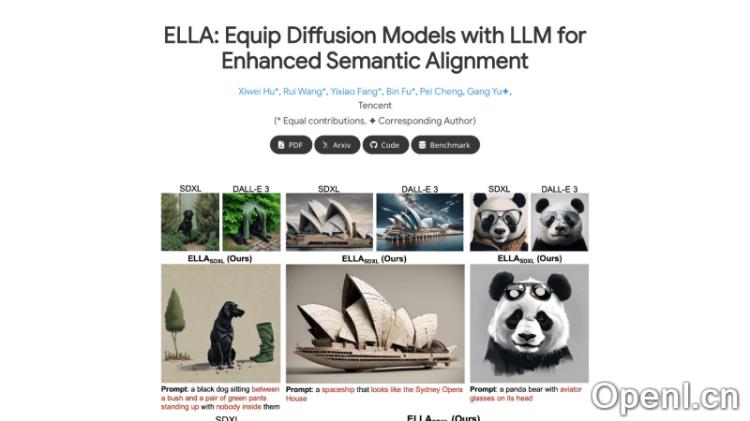
ELLA的官网入口
- 官方项目主页:https://ella-diffusion.github.io/
- GitHub代码库:https://github.com/ELLA-Diffusion/ELLA
- arXiv研究论文:https://arxiv.org/abs/2403.05135
主要功能
- 增强语义对齐:ELLA通过结合大型语言模型(LLM),显著提升了扩散模型对文本提示中多样对象、具体属性和复杂关系的解读能力,从而生成更符合文本内容的图像。
- 时序感知语义提取:ELLA的TSC模块能够依据扩散过程中的不同时间步动态提取语义特征,使得模型在图像生成的不同阶段能够关注不同的文本信息。
- 无需重新训练:ELLA的设计使其可以直接适用于预训练的LLM和U-Net模型,无需额外训练,从而节省了大量的计算资源和时间。
- 良好兼容性:ELLA能够与现有的社区模型(如Stable Diffusion)及下游工具(如ControlNet)无缝对接,提升这些模型和工具在处理复杂文本提示时的表现。
应用场景
ELLA可广泛应用于各类需要图像生成的领域,如艺术创作、广告设计、游戏开发及虚拟现实等。在这些场景中,用户经常需要根据复杂的文本描述生成图像,ELLA则能够有效增强生成结果的质量和准确性。
常见问题
- ELLA适合哪些类型的文本提示?
ELLA特别适合处理包含多个对象、详细属性和复杂关系的长文本提示,能够更好地解析这些信息并生成相应的图像。 - 使用ELLA需要进行额外的训练吗?
不需要。ELLA的设计允许用户在无需重新训练整个模型的情况下,直接应用于现有的LLM和U-Net模型。 - ELLA如何与其他模型兼容?
ELLA可以与多种社区模型及工具无缝集成,提供更强的文本到图像生成能力。
ELLA的工作原理
ELLA的核心机制是通过轻量级的可训练时序感知语义连接器(TSC),将强大的大型语言模型的语义理解能力与现有的图像生成扩散模型相结合,以增强模型对复杂文本提示的理解和图像生成的质量。
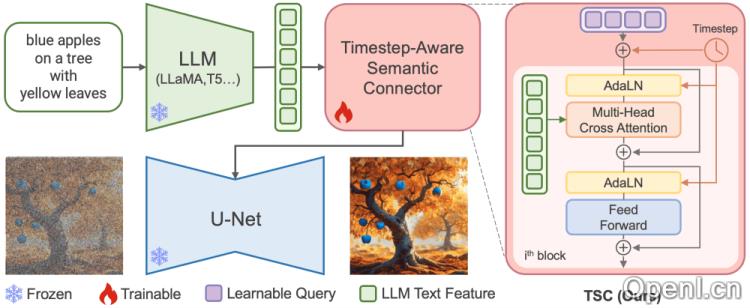
- 文本编码:首先,ELLA利用预训练的大型语言模型(LLM)对输入文本进行编码,提取出丰富的语义特征。
- 时序感知语义连接器(TSC):TSC模块将LLM提取的文本特征与图像生成模型(如U-Net)的扩散过程相结合,依据不同时间步动态调整语义特征,以实现更好的文本与生成图像的对齐。
- 冻结的U-Net:在ELLA架构中,U-Net模型保持冻结状态,避免了整体模型的重新训练,节省了资源并保持原有性能。
- 语义特征适应:TSC模块接收LLM的文本特征和时间步嵌入,输出固定长度的语义查询,通过交叉注意力机制与U-Net模型互动,指导图像生成过程中的噪声预测和去噪步骤。
- 训练TSC模块:尽管LLM和U-Net保持冻结,TSC模块仍需训练,以便在高信息密度的文本-图像对数据集上学习如何提取和调整语义特征。
- 生成图像:在生成图像时,TSC模块依据文本提示和当前的扩散时间步,为U-Net提供条件性特征,帮助生成与文本更紧密对齐的图像。
- 评估和优化:利用如Dense Prompt Graph Benchmark(DPGBench)等基准测试评估增强模型的表现,并根据结果对TSC模块或训练过程进行微调,以进一步提高模型性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。