EMO(Emote Portrait Alive)是阿里巴巴集团智能计算研究院研发的一种创新框架,它能通过单一的参考图像和音频输入,生成富有表现力的面部动画视频。该系统的核心在于其音频驱动的能力,能够捕捉人类面部的细微表情变化,实现高度真实的动态展示。
EMO是什么
EMO(Emote Portrait Alive)是一个由阿里巴巴集团智能计算研究院的研究团队开发的音频驱动AI肖像视频生成框架。用户只需提供一张参考图像和一段音频,就能自动生成具有丰富面部表情和多样头部姿势的视频。它能够精准捕捉人类表情的微妙变化和个体面部风格的多样性,从而生成高度逼真且富有表现力的动画效果。
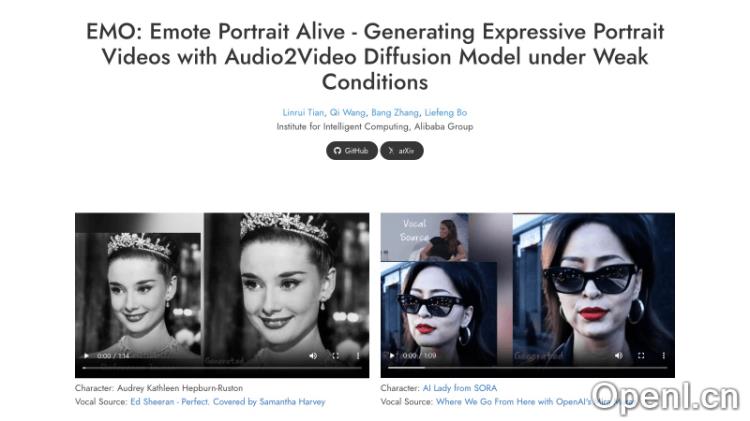
EMO的官网入口
- 官方项目主页:https://humanaigc.github.io/emote-portrait-alive/
- arXiv研究论文:https://arxiv.org/abs/2402.17485
- GitHub:https://github.com/HumanAIGC/EMO(模型和源码即将开源)
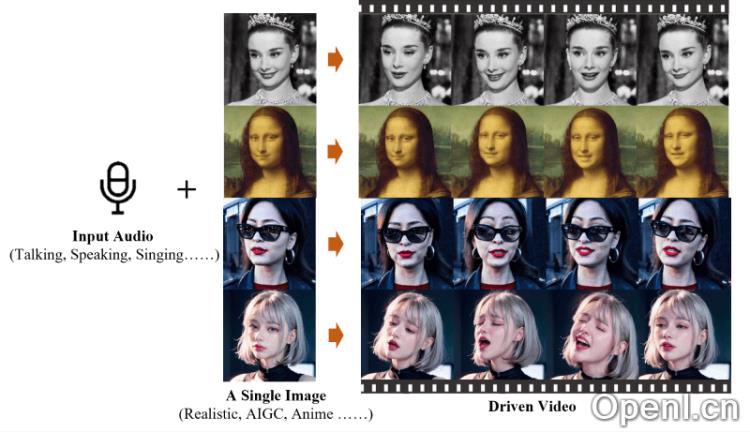
EMO的主要特点
- 音频驱动的视频生成:EMO根据输入的音频信号(如讲话或歌唱)直接生成视频,无需依赖预录制的片段或3D模型。
- 高表现力和逼真度:生成的视频展现出极高的表现力,能够捕捉到人类面部表情的细微变化,包括微表情和与音频节奏相符的头部动作。
- 无缝帧过渡:EMO确保视频帧之间的转换自然流畅,避免面部扭曲或抖动,从而提升视频整体质量。
- 身份保持:借助FrameEncoding模块,EMO在视频生成时保持角色身份一致性,确保角色外观与输入的参考图像相符。
- 稳定的控制机制:EMO引入速度控制器和面部区域控制器等机制,提高视频生成过程中的稳定性,避免崩溃等问题。
- 灵活的视频时长:EMO能够根据音频长度生成任意时长的视频,给予用户更大的创作空间。
- 跨语言和跨风格:EMO的训练数据涵盖多种语言和风格,包括中文和英文,能够适应各种文化和艺术风格。
EMO的工作原理
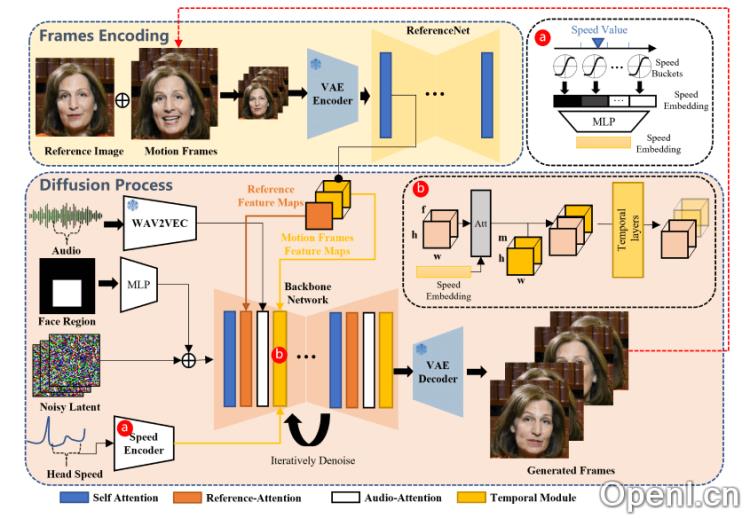
- 输入准备:用户需提供一张参考图像(通常为目标角色的静态肖像)和对应的音频输入(如讲话或歌唱)。这些输入将成为生成视频的基础。
- 特征提取:通过ReferenceNet从参考图像中提取特征,该网络专注于提取输入图像中的详细信息。
- 音频处理:音频输入经过预训练的音频编码器处理,以提取音频特征,这些特征捕捉了语音的节奏、音调及发音等信息,驱动视频中角色的面部表情和头部动作。
- 扩散过程:主网络接收多帧噪声作为输入,并在每个时间步骤中去噪生成连续的视频帧。此过程涉及Reference-Attention和Audio-Attention两个主要机制,前者保持角色身份一致性,后者调节角色动作。
- 时间模块:EMO使用时间模块处理时间维度,以调整动作速度,确保连续帧之间的连贯性和一致性。
- 面部定位和速度控制:面部通过编码面部边界框区域,确保角色动作的稳定性和可控性,而速度层则控制动作的速度和频率。
- 训练策略:EMO的训练分为三个阶段:图像预训练、视频训练和速度层集成,确保音频对角色动作的驱动能力。
- 生成视频:在推理阶段,EMO利用DDIM采样算法生成视频片段,通过迭代去噪过程,最终生成与输入音频同步的肖像视频。
应用场景
EMO的应用潜力广泛,包括虚拟主播、动画制作、社交媒体内容创作以及教育领域的互动课程等。其音频驱动的视频生成能力使得用户可以轻松创建个性化的动态内容,满足不同领域的需求。
常见问题
- EMO支持哪些音频格式? EMO支持多种常见音频格式,包括MP3和WAV。确保音频清晰度,以获得最佳效果。
- 生成视频的时间是多久? 视频生成时间取决于音频长度和系统性能,通常情况下,短音频可以在几分钟内生成视频。
- 我可以使用自己的图像吗? 是的,用户可以使用任意图像作为参考,只要该图像清晰且符合项目要求。
- EMO的输出视频质量如何? EMO能够生成高质量、流畅的视频,细节表现优异,适合多种应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。