JanusFlow是一款由DeepSeek公司推出的先进多模态理解与生成模型,属于其Janus系列。该模型融合了自回归语言模型与校正流技术,能够在同一框架内高效地进行图像理解与生成。通过解耦的视觉编码器和表示对齐策略,JanusFlow在多种任务上展现出卓越的性能,且在多个标准基准测试中取得了与专业模型相媲美或更优的成绩。在视觉理解方面,JanusFlow超越了LLaVA-v1.5与Qwen-VL-Chat,而在图像生成领域,表现优于Stable Diffusion v1.5及SDXL。
JanusFlow是什么
JanusFlow是DeepSeek推出的一款多模态理解与生成模型,旨在统合图像理解与文本到图像生成任务。该模型依托于自回归语言模型和校正流技术,在单一框架内实现高效的功能。其架构采用解耦的视觉编码器和表示对齐策略,从而提升在不同任务上的表现,且在多个基准测试中展现出优异的结果。
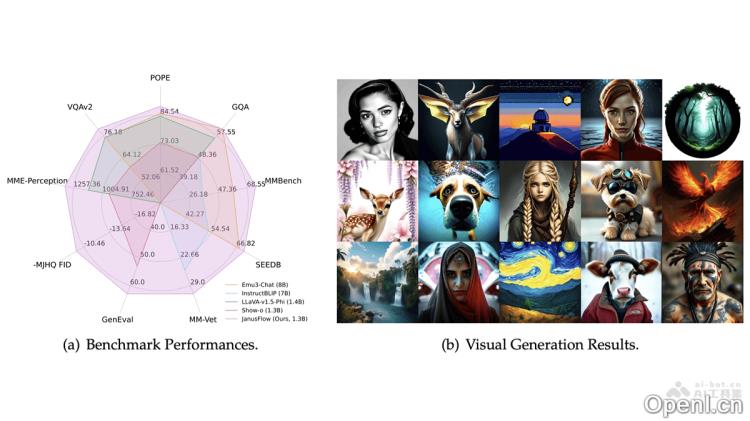
JanusFlow的主要功能
- 多模态理解与生成:JanusFlow能够同时处理图像理解和文本到图像生成的任务,整合在同一个模型框架中。
- 自回归语言模型的集成:基于大型语言模型的能力,JanusFlow可以学习并泛化新的场景信息。
- 校正流技术:通过校正流技术,JanusFlow在生成建模中提供了简单有效的框架,确保高质量的图像生成。
- 解耦视觉编码器:为理解和生成任务分别设计不同的视觉编码器,从而增强模型在特定任务上的性能。
- 表示对齐机制:在训练过程中,通过对齐生成和理解模块的中间表示,提升生成过程中的语义一致性。
JanusFlow的技术原理
- 架构整合:
- 自回归语言模型:JanusFlow利用自回归语言模型处理文本数据,实现自然语言的理解与生成。
- 校正流:引入校正流技术,基于学习到的数据分布通过普通微分方程(ODE)生成数据。
- 解耦编码器设计:
- 理解编码器:采用预训练的视觉编码器(如SigLIP-Large-Patch/16)来提取图像的语义特征。
- 生成编码器:使用的ConvNeXt模块作为生成任务的视觉编码器,提升生成图像的质量。
- 表示对齐策略:在训练过程中,将理解编码器的特征与语言模型的中间特征进行对齐,以增强生成过程中的语义一致性。
- 训练策略:包括对组件的随机初始化、统一预训练和监督微调,结合自回归目标、校正流目标及表示对齐正则化,以优化模型性能。
- 性能优化:在生成过程中通过CFG增强图像的语义对齐,通过调整CFG因子和采样步数等超参数,提升生成图像的质量与一致性。
JanusFlow的项目地址
- GitHub仓库:https://github.com/deepseek-ai/Janus
- arXiv技术论文:https://arxiv.org/pdf/2411.07975
- 在线体验Demo:https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B
JanusFlow的应用场景
- 图像生成:根据文本描述生成相应图像,适用于广告、游戏开发及艺术创作等领域。
- 多模态内容创作:结合文本与图像,创造新的媒体内容,广泛应用于社交媒体、新闻报道及教育材料的制作。
- 视觉问答(Visual QA):在教育、博物馆导览或智能助手中,回答与图像相关的问题,提供更为丰富的信息。
- 图像理解与分析:在安全监控、医疗影像分析等领域,对图像内容进行深入理解与分类。
- 辅助设计与规划:在建筑和城市规划中,根据需求生成设计方案的视觉表现。
常见问题
- JanusFlow支持哪些任务?:JanusFlow可用于图像理解、文本到图像生成、视觉问答等多种任务。
- 如何获取JanusFlow的最新信息?:可以通过访问其GitHub仓库或arXiv技术论文来获取最新的信息与更新。
- 是否可以在线体验JanusFlow?:是的,用户可以通过提供的在线Demo链接进行体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。