Voyage Multimodal-3 是 Voyage AI 最新推出的多模态嵌入模型,具备处理交错文本与图像的能力。该模型能够从 PDF、幻灯片和表格等截图中精准捕捉重要视觉特征,且无需依赖繁琐的文档解析。Voyage Multimodal-3 在多模态检索任务中的表现尤为突出,平均检索准确率比目前最优模型高出19.63%。它支持文本和丰富图像内容的处理,采用现代视觉-语言转换器的架构,能够高效整合文本与视觉数据,提供更为精准的语义搜索与文档理解能力。
Voyage Multimodal-3是什么
Voyage Multimodal-3 是一款由 Voyage AI 开发的先进多模态嵌入模型,专门用于处理交错的文本和图像,并能从各种格式的截图中提取关键视觉特征,而无需复杂的文档解析流程。该模型在多模态检索方面表现卓越,其平均检索准确率比现有的最佳模型高出19.63%。它支持文本以及内容丰富的图像,具有类似现代视觉-语言转换器的架构,能够统一处理文本和视觉数据,从而提供更为准确的语义搜索和文档理解能力。
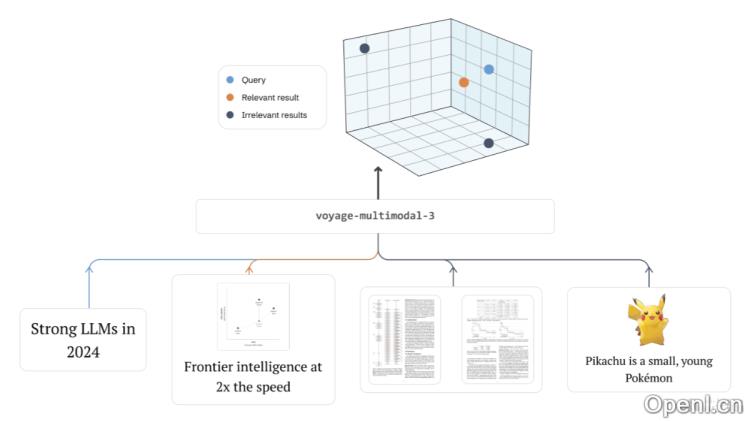
Voyage Multimodal-3 的主要功能
- 多模态数据处理:具备处理和理解文本、图像以及混合类型数据的能力,适用于 PDF、幻灯片、表格等截图。
- 交错文本和图像矢量化:支持对交叉数据进行矢量化处理,提升数据处理的灵活性和效率。
- 关键视觉特征捕捉:从各种视觉内容中提取重要特征,如字体大小、文本位置和空白等元素。
- 无需复杂文档解析:消除了对复杂文档解析的依赖,提高了处理的效率和准确性。
- 语义搜索与RAG支持:为包含丰富视觉和文本信息的文档提供无缝的检索增强生成(RAG)和语义搜索功能。
Voyage Multimodal-3 的技术原理
- Transformer 架构:Voyage Multimodal-3 的架构基于现代视觉-语言转换器,使用 Transformer 编码器处理数据。
- 统一编码器:在同一 Transformer 编码器中直接对文本和图像数据进行矢量化,确保两者的特征被整合为统一的表征。
- 特征提取:利用先进的特征提取技术,捕捉文本和视觉内容中的关键特征,如字体大小和文本位置。
- 模态融合:通过融合不同模态的特征,使得模型能够更好地理解和关联文本与视觉信息。
- 混合模态搜索:优化混合模态搜索,减少模态间的差距,提升检索质量。
Voyage Multimodal-3 的项目地址
Voyage Multimodal-3 的应用场景
- 智能文档检索:在法律、金融、医疗等领域,能够检索包含文本和图表的复杂文档,如合同、研究报告和医疗记录。
- 知识库搜索:对于包含丰富视觉和文本信息的知识库,提供更为精准的语义搜索,帮助用户快速获取所需信息。
- 教育与学术研究:在学术研究中,协助研究人员快速检索包含图表、公式和文本的学术论文和资料。
- 电子商务:在电商平台中,支持图像搜索,帮助用户通过上传图片或描述找到相关产品。
- 内容推荐系统:结合用户的历史行为和偏好,推荐包含图像和文本的相关内容,如新闻文章和博客帖子。
常见问题
- Voyage Multimodal-3 支持哪些文件格式?:该模型支持多种文件格式,包括 PDF、幻灯片和表格截图。
- 如何提高检索准确率?:通过使用 Voyage Multimodal-3 进行数据处理和检索,能够显著提升检索准确率。
- 能否与现有系统集成?:是的,Voyage Multimodal-3 设计上可与现有系统无缝集成,提高文档处理和搜索的效率。
- 支持哪些语言?:该模型支持多种语言的文本处理,具体支持的语言请参考官方文档。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。