Florence-2 是由微软 Azure AI 团队开发的一款多功能视觉模型,具备强大的计算机视觉能力,能够执行图像描述、目标检测、视觉定位和图像分割等多种任务。该模型采用了 Transformer 架构,利用序列到序列学习的方法,将图像编码为序列表示,并通过解码器将其转换为文本输出。Florence-2 的训练数据来自一个包含1.26亿张图像和54亿个标注的超大数据集 FLD-5B,结合了自动化图像标注技术和模型迭代,确保了数据的高质量和多样性。
Florence-2是什么
Florence-2 是微软 Azure AI 团队推出的创新视觉模型,能够高效执行多种计算机视觉任务,包括图像描述、目标检测、视觉定位和图像分割。该模型基于先进的 Transformer 架构,采用序列到序列的学习方法,将输入图像转换为序列表示,并生成相应的文本描述。Florence-2 的训练依赖于一个超大规模的数据集,确保了其在多样性和准确性方面的卓越表现。
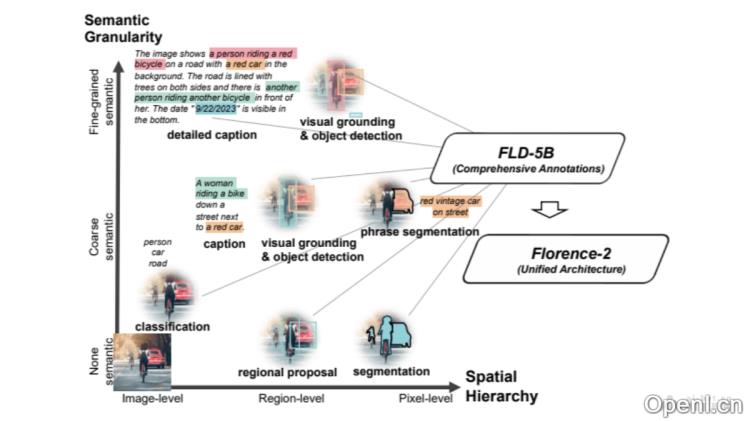
主要功能
- 图像描述:为图像生成详细的描述,类似于图像的字幕。
- 目标检测:识别图像中特定对象,并确定其位置。
- 视觉定位:根据文本提示,在图像中定位相关对象或区域。
- 图像分割:将图像划分为不同的区域,以识别和分离特定对象。
产品官网
- 项目官网:florence-2.com
- GitHub仓库:https://github.com/retkowsky/florence-2
- HuggingFace模型库:https://huggingface.co/microsoft/Florence-2-large
- arXiv技术论文:https://arxiv.org/pdf/2311.06242
应用场景
- 图像和视频分析:在安全监控领域,Florence-2 可以识别和跟踪视频中的特定对象,进行异常行为检测。
- 内容审核:自动检测和过滤不适当内容,如暴力、或其他违反平台政策的图像和视频。
- 辅助驾驶和自动驾驶:在自动驾驶系统中,帮助识别道路标志、行人、车辆及其他障碍物,以提升行车安全。
- 医疗影像分析:辅助医生识别医学图像中的异常,如肿瘤和病变,提高诊断的准确性和效率。
- 零售和库存管理:在零售环境中,实现货架分析,自动监测库存水平和产品摆放。
常见问题
- Florence-2的主要优势是什么? Florence-2 通过统一的模型架构,能够处理多种视觉任务,极大提高了应用的灵活性和效率。
- 如何获取Florence-2的使用权限? 用户可以通过访问官方网站或相关GitHub仓库获取使用文档和示例代码。
- Florence-2是否支持多语言? 是的,Florence-2 能够生成多种语言的图像描述,适应不同市场的需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。