Free Video-LLM是一款创新的高效视频语言模型,旨在无需额外训练的情况下,实现对视频内容的深度理解。该模型基于提示引导的视觉感知技术,能够有效识别视频中的重要信息,显著减少所需的视觉标记数量,从而降低计算成本;同时,它在多个视频问答基准测试中展现出与顶尖视频LLMs相媲美的性能,成为视频理解任务中准确性与计算效率的理想平衡点。
Free Video-LLM是什么
Free Video-LLM是先进的高效视频语言模型,采用无需训练的方式,利用提示引导的视觉感知技术,以实现对视频内容的精准理解。该模型结合了预训练的图像LLMs,能够快速适应各种视频相关任务,减少视觉标记的使用,从而降低计算开销。在多个视频问答基准上,Free Video-LLM的表现与业界最前沿的视频LLMs相当,展示了其在视频理解方面的强大能力。
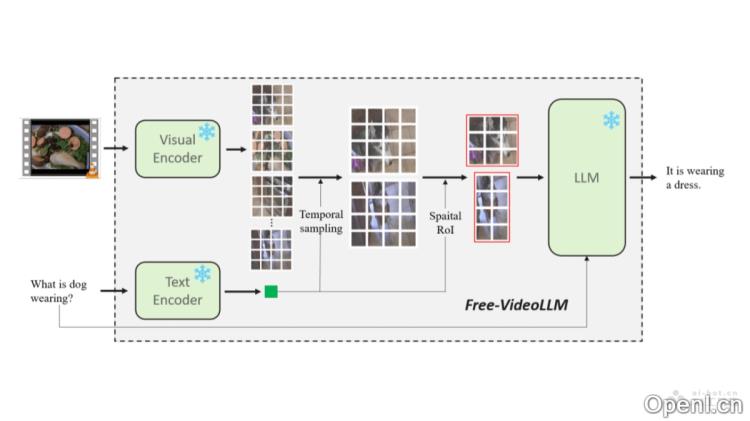
Free Video-LLM的主要功能
- 高效视频理解:无需额外训练,模型可直接理解和推理视频内容,特别适合视频问答等多模态任务。
- 提示引导的视觉感知:通过分析输入提示,模型能够识别与任务相关的时空信息,避免不必要的计算。
- 时空采样优化:利用时间帧采样和空间兴趣区域(RoI)裁剪技术,减少处理的视频数据量,提升推理效率。
- 保持高性能:尽管减少了视觉标记,模型在多个视频问答基准测试中依然保持与现有技术相竞争的高性能。
Free Video-LLM的技术原理
- 提示引导的时间采样:通过与视觉编码器相匹配的文本编码器提取提示特征,计算视频帧特征与提示特征之间的相似度,并根据得分进行相关帧的选择。
- 提示引导的空间采样(RoI裁剪):将视频帧的视觉标记重塑为空间维度,计算每个空间位置的特征向量与提示特征的相似度得分,选择最相关的区域进行裁剪。
- 减少视觉标记:采用时空采样方法,有效降低模型处理的视觉标记数量,从而简化计算复杂度。
- 保持性能:通过精心设计的采样策略,模型即使在减少视觉标记的情况下,仍能保持或提升视频理解任务的性能。
Free Video-LLM的项目地址
- GitHub仓库:https://github.com/contrastive/FreeVideoLLM
- arXiv技术论文:https://arxiv.org/pdf/2410.10441
Free Video-LLM的应用场景
- 视频问答系统:自动提供视频内容的问答服务,适用于教育平台的辅导视频或企业培训视频的理解。
- 视频内容分析:在媒体与娱乐行业中,自动提取视频的语义信息,以便于内容管理和检索。
- 安全监控:在安全领域,实时分析监控视频,识别特定或行为。
- 自动驾驶:帮助自动驾驶汽车理解视频流中的道路状况,辅助决策制定。
- 智能助理:集成至智能助理中,提供基于视频内容的互动问答功能。
常见问题
- Free Video-LLM是否需要额外训练? 不需要,模型已通过预训练的图像LLMs进行优化,能够直接适应视频任务。
- 该模型在哪些任务中表现最佳? Free Video-LLM在视频问答、内容分析等多模态任务中表现出色。
- 如何访问Free Video-LLM的源代码? 您可以访问其GitHub仓库,链接在上文中提供。
- Free Video-LLM的性能如何? 该模型在多个视频问答基准上与现有视频LLMs的表现相当,表现优异。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。