JoyVASA是京东健康国际公司推出的一个开源音频驱动数字人头项目,利用先进的扩散模型技术,根据音频信号生成与之同步的面部动态和头部。其独特之处在于能够实现人物的唇形同步和表情控制,并且支持动物头像的动画生成,展示了在多语言支持和跨物种动画化方面的广泛应用潜力。
JoyVASA是什么
JoyVASA是京东健康国际公司开源的音频驱动数字人头项目,基于扩散模型技术,能够根据音频信号生成与音频同步的面部动态和头部。JoyVASA不仅可以实现人物的唇形同步和表情控制,还能扩展到动物头像的动画生成,具备多语言支持和跨物种动画化的广泛应用潜力。
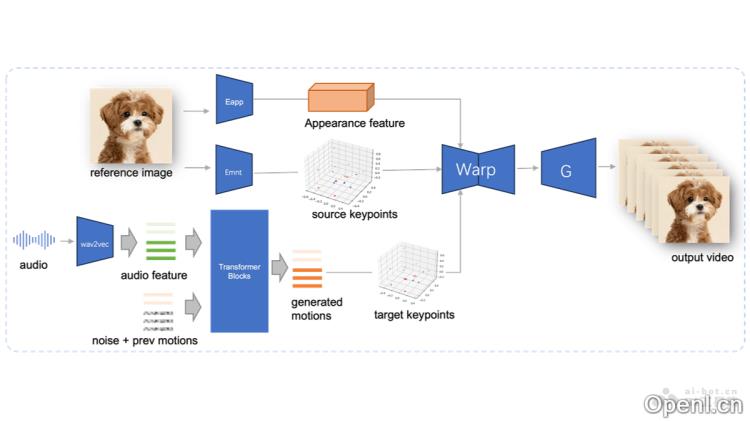
JoyVASA的主要功能
- 音频驱动的面部动画:根据输入的音频信号生成与之同步的面部动画,包括嘴唇动作和表情变化。
- 唇形同步:通过精确匹配音频与嘴唇动作,实现真实的对话效果。
- 表情控制:能够控制和生成特定的面部表情,以增强动画的表现力。
- 动物面部动画:JoyVASA具备生成动物面部动态的能力,扩展了应用范围。
- 多语言支持:项目在包含中文与英文的数据集上进行训练,因此支持多种语言的动画生成。
- 高质量视频生成:该项目能够生成高分辨率和高质量的动画视频,提升观看体验。
JoyVASA的技术原理
- 解耦面部表示:JoyVASA利用解耦的面部表示框架,将动态表情与静态3D面部特征分离,从而生成更长的视频。
- 扩散模型:该项目使用扩散模型直接从音频提示生成序列,序列与角色身份无关。
- 两阶段训练:
- 第一阶段:分离静态面部特征和动态特征,静态特征捕捉面部的身份特征,动态特征则编码面部表情、缩放、旋转和平移等动态元素。
- 第二阶段:训练一个扩散变换器,从音频特征中生成特征。
- 音频特征提取:使用wav2vec2编码器提取输入语音的音频特征,作为生成序列的依据。
- 序列生成:基于扩散模型在滑动窗口中采样音频驱动的序列,包括面部表情和头部。
JoyVASA的项目地址
- 项目官网:jdh-algo.github.io/JoyVASA
- GitHub仓库:https://github.com/jdh-algo/JoyVASA
- HuggingFace模型库:https://huggingface.co/jdh-algo/JoyVASA
- arXiv技术论文:https://arxiv.org/pdf/2411.09209
JoyVASA的应用场景
- 虚拟助手:在智能家居、客户服务和技术支持领域,为虚拟助手提供逼真的面部动画和表情,提升用户的交互体验。
- 娱乐和媒体:用于生成或增强角色的面部表情和动作,减少传统动作捕捉的需求,为游戏角色提供更加自然的面部表情和动画,提升游戏的沉浸感。
- 社交媒体:用户可以利用JoyVASA生成自己的虚拟形象,适用于视频或社交媒体平台的内容创作。
- 教育和培训:在在线教育平台中,创建虚拟教师,提供更具吸引力的教学体验。在医疗、军事等领域,模拟人物反应和表情,作为专业训练的工具。
- 广告和营销:打造引人注目的虚拟代言人,用于广告宣传,提高品牌形象的吸引力。
常见问题
1. JoyVASA支持哪些语言?
JoyVASA支持多语言动画生成,包括中文和英文。
2. 如何获取JoyVASA的源代码?
您可以通过访问其GitHub仓库获取源代码。
3. JoyVASA适用于哪些行业?
JoyVASA在虚拟助手、娱乐、社交媒体、教育和广告等多个行业中都具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。