WorldDreamer是一款基于Transformer架构的通用世界模型,旨在深入理解和预测物理世界的变迁与规律,显著提升视频生成的能力。它能够处理多种视频生成任务,包括图像转视频、文本转视频、视频编辑和动作序列视频生成等,尤其在自然场景和自动驾驶环境中表现出色。
WorldDreamer是什么
WorldDreamer是一个创新的通用世界模型,利用Transformer架构来理解和预测物理世界的变化与规律,增强视频生成的能力。该模型可以完成多种视频生成任务,适用于自然场景及自动驾驶的应用。通过将视觉输入映射为离散标记并预测被遮蔽的标记,WorldDreamer结合多模态提示以促进内部交互。实验结果表明,WorldDreamer在生成不同场景中的视频时表现优异,展现了其在文本到视频转换、图像到视频合成和视频编辑等任务中的多样性。
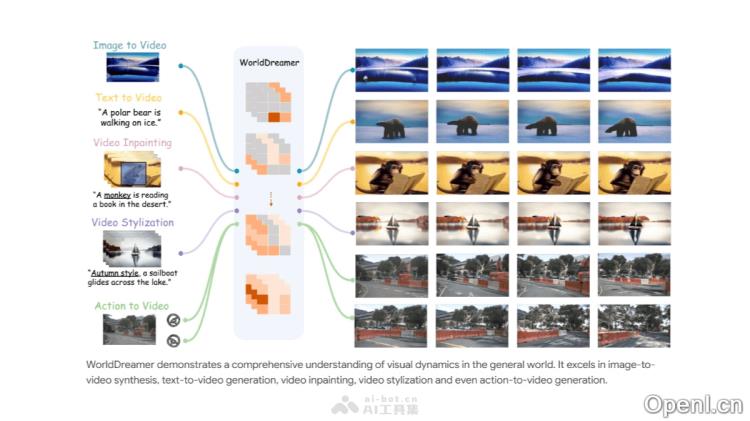
WorldDreamer的主要功能
- 图像转视频(Image to Video):通过处理单一图像,预测未来的视频帧,视其他视频帧为被掩蔽的视觉Token,从而生成高质量且连贯的视频内容。
- 文本转视频(Text to Video):仅依赖于语言文本输入,WorldDreamer可以预测相应的视频,假设所有视觉标记都被屏蔽,从而生成符合文本描述的视频。
- 视频修改(Video Inpainting):在已有视频上指定需要修改的区域,通过语言输入调整被遮蔽区域的内容,实现局部视频修改与内容替换。
- 视频风格化(Video Stylization):输入视频段并随机遮蔽某些像素,WorldDreamer能够根据语言输入改变视频风格,创造特定的主题效果。
- 基于动作合成视频(Action to Video):在自动驾驶场景中,根据初始帧和后续驾驶指令,WorldDreamer预测未来的视频帧,生成符合驾驶动作的视频。
WorldDreamer的技术原理
- 视觉Token化:通过VQGAN将图像和视频编码为离散的视觉Token,使连续视觉信号能够被模型处理。
- Transformer架构:基于Transformer架构,WorldDreamer构建了一种通用的世界模型,旨在理解和预测视觉信号中的动态和物理规律。
- 时空补丁Transformer (STPT):为应对视频信号的时空特性,WorldDreamer引入STPT,使注意力集中在时空窗口内的局部补丁上,从而加速对视觉动态的学习。
- 多模态提示:通过交叉注意力机制整合语言和动作信号,WorldDreamer构建多模态提示,促进在世界模型内的有效交互。
- 预测被掩盖的视觉Token:WorldDreamer将世界建模框架转变为一个无监督的视觉Token预测问题,通过预测被遮蔽的视觉Token捕捉视觉数据中的潜在和物理规律。
- 并行解码视频:与以扩散为基础的方法相比,WorldDreamer展现了卓越的解码速度,只需数次迭代即可并行解码视频,速度约为扩散方法的三倍。
- 无监督学习:支持无监督学习,WorldDreamer通过预测被遮蔽的视觉Token进行训练,无需额外的监督信号。
WorldDreamer的项目地址
- 项目官网:world-dreamer.github.io
- Github仓库:https://github.com/JeffWang987/WorldDreamer
- arXiv技术论文:https://arxiv.org/pdf/2401.09985
WorldDreamer的应用场景
- 自然场景视频生成:WorldDreamer能够根据自然场景的图像或文本描述生成相应的视频内容,适用于模拟和展示多种自然风光和动物行为。
- 驾驶环境视频生成:在自动驾驶领域,WorldDreamer可根据驾驶动作或初始帧生成后续视频,模拟不同驾驶策略下的车辆,为自动驾驶技术提供重要的模拟训练数据。
- 视频编辑:支持视频的修复与修改,用户可根据语言输入指定区域进行内容更改,以确保视频与用户描述的高度一致,实现精细化编辑。
- 图像到视频合成:WorldDreamer能够从单一图像中预测未来的帧,实现高质量视频的生成,呈现出如电影般流畅的效果,同时保持原始图像的一致性。
- 文本到视频生成:通过文本内容生成视频,实现语言与视频内容的完美结合,用户可根据语言输入自定义视频内容、风格和镜头。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。