StoryTeller是什么
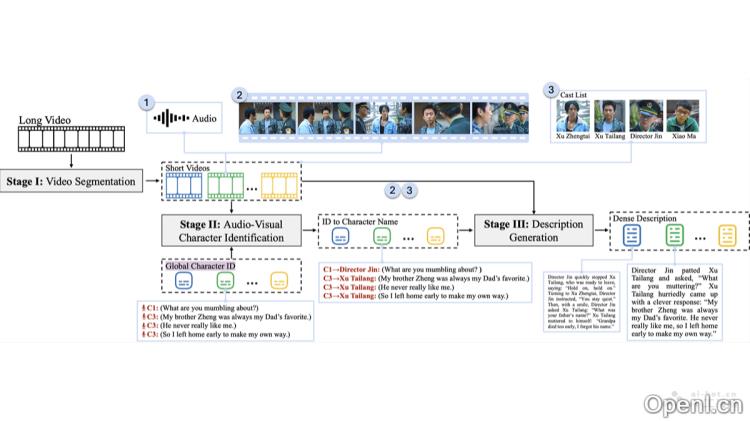
StoryTeller是由字节跳动、上海交通大学与北京大合研发的一种创新系统,旨在通过音频视觉角色识别技术提升长视频的描述质量与一致性。该系统巧妙地结合了基础视觉概念与复杂剧情信息,能够生成详尽且连贯的视频叙述。StoryTeller主要由三个模块构成:视频分割、音频视觉角色识别和描述生成,能够有效处理时长数分钟的视频。在MovieQA任务中,StoryTeller的准确率超过了现有模型,较最强基线Gemini-1.5-pro提升了9.5%。
StoryTeller的主要功能
- 视频分割:将较长的视频切分为多个短片段,确保每个片段且完整。
- 音频视觉角色识别:通过整合音频和视觉信息,识别视频中对话所对应的角色。
- 描述生成:为每个视频片段创建详尽的描述,并整合成连贯的整体叙述。
- 数据集构建:构建并运用MovieStory101数据集,为长视频描述提供训练和测试的数据基础。
- 自动评估:基于MovieQA,通过GPT-4自动评价视频描述的准确性与质量。
- 模型训练与微调:对多模态大型语言模型进行训练,提升角色识别和视频描述的准确性。
- 全局解码:确保在不同视频片段中,同一角色保持一致的识别结果。
StoryTeller的技术原理
- 多模态融合:融合视觉(视频帧)、音频(对话)和文本(字幕及描述)信息,全面理解视频内容。
- 音频分离与角色ID分配:通过音频嵌入模型对每个对话进行嵌入,利用聚类算法分配全局ID,将相似的音频嵌入标记为同一角色。
- 音频视觉角色识别模型:结合大型语言模型(如Tarsier-7B)与OpenAI的Whisper-large-v2音频编码器,将每个音频ID映射到特定角色。
- 全局解码算法:在推理过程中,确保不同片段中同一角色的全局ID映射到一致的角色名称,从而提高角色识别的准确性。
- 视频描述生成:利用识别结果作为输入,基于大型语言模型为每个片段生成详细描述,并整合成完整的视频叙述。
StoryTeller的项目地址
- GitHub仓库:https://github.com/hyc2026/StoryTeller
- arXiv技术论文:https://arxiv.org/pdf/2411.07076
StoryTeller的应用场景
- 电影与视频内容制作:自动生成电影预告片或片段描述,帮助导演和编剧迅速把握视频内容,辅助视频编辑人员快速定位关键片段。
- 视频内容分析:在视频分析领域,提取视频内容的核心信息,如角色、情节和动作,进行深度分析。
- 辅助视障人士:为视障人士提供视频内容的音频描述,帮助他们更好地理解视频情节。
- 教育与培训:在教育领域,为学生提供视频教材的详细描述,增强学习体验;在职业培训中,生成视频教程的详细步骤描述,提高培训效率。
- 视频搜索与索引:提升视频搜索的准确性,基于视频描述快速检索相关片段。
常见问题
- StoryTeller支持哪些视频格式?:StoryTeller能够处理多种常见的视频格式,具体支持的格式请参考官方网站的文档。
- 如何使用StoryTeller生成视频描述?:用户只需将视频上传至系统,StoryTeller将自动进行处理并生成描述。
- 是否需要专业知识才能使用StoryTeller?:StoryTeller的设计旨在友好易用,用户无需具备专业技术背景即可操作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。