原标题:多模态新思路:Next-Token Prediction is All You Need 主体模型代码介绍
文章来源:小夏聊AIGC
内容字数:46字
Emu3模型使用教程
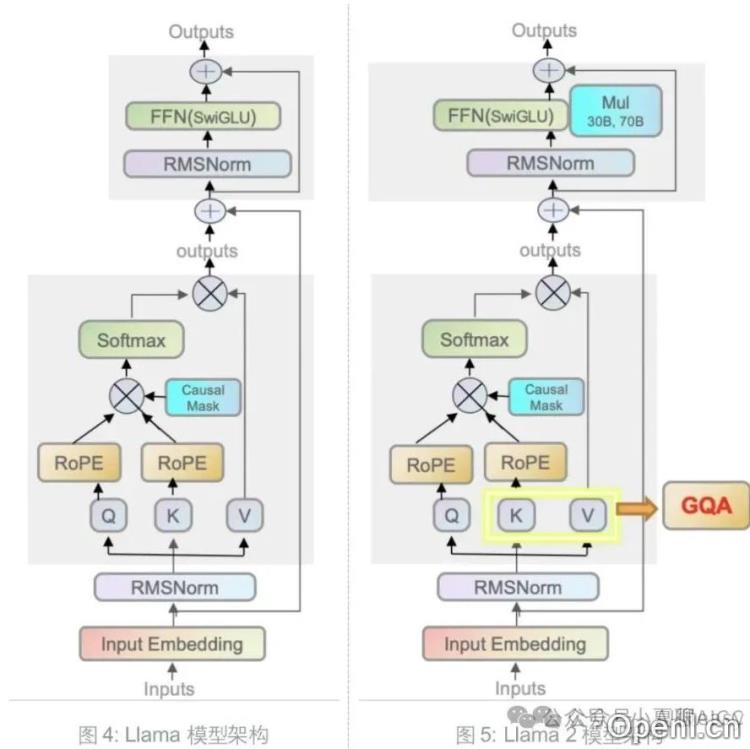
欢迎使用Emu3模型!本教程将帮助您快速上手并有效利用该模型的功能。Emu3以其与Llama2相似的结构而受到广泛关注,以下是一些基本的使用步骤和注意事项。
1. 环境准备
在使用Emu3模型之前,请确保您的计算环境满足以下要求:
- 安装Python 3.7及以上版本。
- 确保安装了必要的深度学习库,如TensorFlow或PyTorch。
- 准备好相应的GPU支持,以提高模型的运行效率。
2. 模型安装
您可以通过以下命令安装Emu3模型:
pip install emu3-model
安装完成后,您可以通过以下代码导入模型:
from emu3 import Emu3Model
3. 模型初始化
在使用模型之前,需要进行初始化设置:
model = Emu3Model()
您还可以根据需要加载预训练的权重:
model.load_weights('path/to/weights')
4. 数据准备
在进行推理或训练之前,请确保准备好输入数据。数据应符合模型要求的格式:
- 文本数据应进行适当的预处理,如分词和标准化。
- 确保数据集的大小和质量,以获得更好的结果。
5. 模型推理
使用模型进行推理非常简单。您只需调用模型的推理方法并传入数据:
output = model.predict(input_data)
这里的应为您准备好的输入数据。
6. 模型训练
如果您希望对模型进行微调,可以使用以下代码进行训练:
model.train(training_data,epochs=10)
请根据您的数据集和需求调整训练参数。
7. 结果分析
训练和推理完成后,您可以对结果进行分析。根据输出结果,您可以评估模型的性能并进行必要的调整。
8. 常见问题
在使用Emu3模型时,可能会遇到一些常见问题:
- 如果模型运行缓慢,请检查您的硬件配置,确保使用了GPU。
- 如果遇到内存不足的问题,尝试减少输入数据的批次大小。
结语
感谢您阅读本教程,希望您能顺利使用Emu3模型进行各种应用。如果您有任何问题,请参考官方文档或社区支持。
联系作者
文章来源:小夏聊AIGC
作者微信:
作者简介:专注于人工智能生成内容的前沿信息与技术分享。我们提供AI生成艺术、文本、音乐、视频等领域的最新动态与应用案例。每日新闻速递、技术解读、行业分析、专家观点和创意展示。期待与您一起探索AI的无限潜力。欢迎关注并分享您的AI作品或宝贵意见。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。