目前市场上最小的视觉语言模型之一
原标题:Omnivision-968M:最小多模态模型,为边缘设备而生!
文章来源:智猩猩GenAI
内容字数:3871字
2024中国生成式AI大会(上海站)预告
智猩猩联合主办的2024中国生成式AI大会将于12月5日至6日在上海举办。此次大会将设有主会场和分会场,主会场将举行大模型峰会和AI Infra峰会,分会场将进行端侧生成式AI、AI视频生成和具身智能三场技术研讨会。大会吸引了50多位重磅嘉宾参与主题演讲、高端对话和圆桌讨论,完整议程已正式公布,欢迎大家报名参加。
Omnivision-968M模型介绍
最近,在HuggingFace上备受关注的开源多模态模型Omnivision-968M,由创业公司Nexa AI推出。该模型具备不到1B参数量的小巧体积(仅968M参数量),成为市场上最小的视觉语言模型之一。Nexa AI的愿景是将先进的端侧AI模型带到本地设备上,降低成本并提升用户隐私安全。
模型性能与特点
Omnivision-968M在推理速度上表现优异,能够在Apple M4 Pro处理器的MacBook上以不到2秒的速度生成1046×1568像素图像的语言描述,同时仅占用988MB的统一内存。该模型相较于标准LLaVA架构进行了两大改进:其一,图像Token从729减少到81,实现了9倍的Token压缩;其二,通过使用可信数据进行DPO训练,降低幻觉现象,提高了结果的可靠性。
模型结构与训练方法
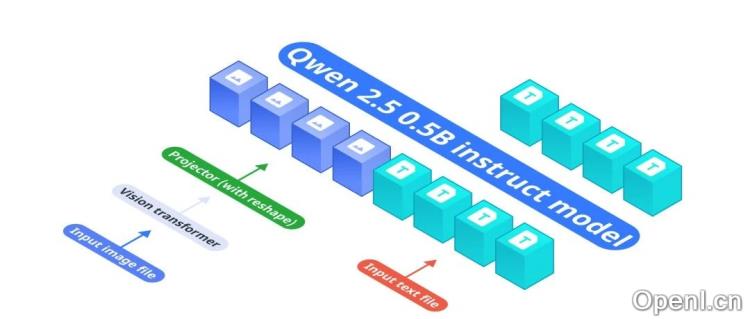
Omnivision的架构由三个关键组件构成:基础语言模型Qwen2.5-0.5B-Instruct、视觉编码器SigLIP-400M和投影层MLP。在训练阶段,Omnivision首先进行预训练,建立视觉-语言对齐,然后通过图像问答数据集增强模型的上下文理解能力,最后采用直接偏好优化(DPO)进行微调,确保模型在不改变核心响应特征的情况下进行必要的改进。
实验与性能评测
性能评测显示,Omnivision在多个任务中表现优于之前的视觉语言模型nanoLLAVA,但略逊于Qwen2-VL-2B。Omnivision能够在生成图像描述、寻找图像目标、分析食物图像生成食谱等任务中展现出其强大的能力。
总之,Omnivision-968M以其高效的性能和小巧的体积,展示了端侧生成式AI模型的未来潜力,为用户提供了更为安全和高效的AI解决方案。期待在即将举行的2024中国生成式AI大会上,听到更多关于这一模型的讨论与应用案例。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。