探索不同的对齐方法对MLLMs性能的影响~
原标题:ICLR 高分:深入研究多模态大模型的对齐策略
文章来源:智猩猩GenAI
内容字数:9223字
2024中国生成式AI大会(上海站)预告
2024中国生成式AI大会将于12月5-6日在上海举办,由智猩猩联合主办。大会将设主会场和分会场,主会场将进行大模型峰会和AI Infra峰会,分会场则将举行针对端侧生成式AI、AI视频生成和具身智能的技术研讨会,欢迎各界人士报名参加。
多模态大模型(MLLMs)研究背景
多模态大模型在视觉与语言理解任务上取得了显著进展,但仍面临“幻觉”现象,即生成的描述可能不符合视觉内容。为了解决这一问题,研究人员提出了偏好对齐(preference alignment)方法来增强模型与图像内容的契合度。
研究主要贡献
- 对齐方法分类:将偏好对齐方法分为离线方法(如DPO)和在线方法(如在线DPO),并探讨了结合两者的优势。
- 偏好数据集分析:回顾并分析了多种已发布的偏好数据集,探讨其构建细节对模型表现的影响。
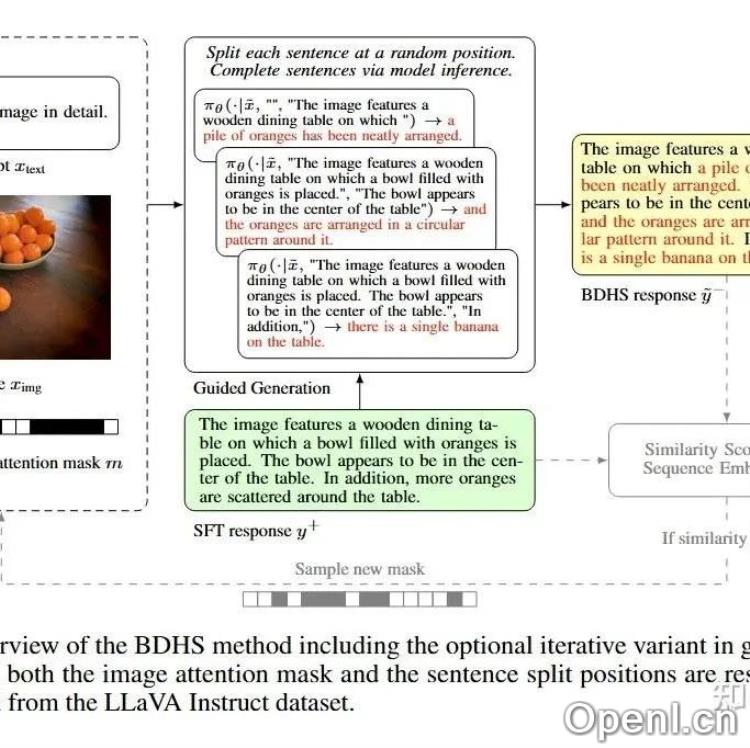
- 新偏好数据采样方法:提出“偏差驱动幻觉采样”(BDHS),无需额外人工标注,依靠偏差驱动的采样生成对齐数据。
- 系统化实验验证:在多个基准任务上验证BDHS的有效性,展示其在减少幻觉现象方面的优势。
技术细节与实验发现
多模态偏好数据由提示语、优选响应和拒绝响应组成。研究表明,使用多样化的提示和选定响应能显著提升对齐效果。同时,BDHS方法通过注意力屏蔽的方式诱导模型产生幻觉响应,并进行语义相似度检测以确保响应质量。实验结果显示,离线DPO在减少幻觉方面表现尤为突出,而混合DPO则结合了在线和离线方法的优势。另外,使用强标注器能提升模型的对齐质量。
结论与未来展望
本研究探讨了偏好对齐在提升MLLM性能方面的作用,并提出新型偏好数据集和BDHS采样策略。虽然当前研究已揭示了一些关键进展与挑战,但在LLM和MLLM之间仍存在显著差距。未来的研究应进一步探索在线对齐方法以及幻觉基准的开发,助力该领域的持续发展。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。