EfficientTAM是一款由Meta AI推出的轻量级视频对象分割和跟踪模型,旨在解决在移动设备上部署SAM 2模型时面临的高计算复杂度难题。通过采用简单的非层次化Vision Transformer(ViT)作为图像编码器,并引入高效的记忆模块,EfficientTAM在保证分割质量的同时,显著降低了延迟和模型大小。该模型在多个视频分割基准测试中展现出与SAM 2相当的性能,具备更快的处理速度和更少的参数,特别适合用于移动设备的视频对象分割应用。
EfficientTAM是什么
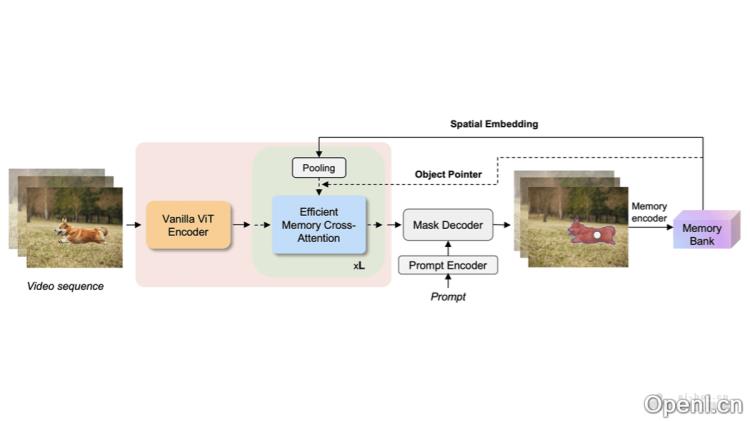
EfficientTAM是Meta AI开发的一款轻量级视频对象分割与跟踪模型,专为解决SAM 2在移动设备上部署时的高计算复杂度问题而设计。它采用非层次化的Vision Transformer(ViT)作为图像编码器,并通过高效的记忆模块来降低计算复杂度,从而在保持分割质量的前提下,减少延迟和模型体积。EfficientTAM在众多视频分割基准测试中表现优异,尤其适合在移动设备上进行视频对象分割。
主要功能
- 视频对象分割:能够从视频帧中准确分割出用户感兴趣的对象。
- 多对象跟踪:支持在视频中同时跟踪多个对象,提升应用的灵活性。
- 轻量化设计:经过特别优化,模型在资源受限的设备上(如智能手机)也能实现实时视频处理。
- 高质量输出:尽管模型轻量化,依然能够产生高精度的分割结果,满足对精度要求严格的应用场景。
- 低延迟分析:在进行复杂视频分析任务时,能够保持较低的延迟。
技术原理
- 非层次化Vision Transformer (ViT):采用简单的非层次化ViT作为图像编码器,相较于传统的多阶段编码器,ViT在特征提取上更为高效。
- 高效记忆模块:通过引入高效记忆模块,存储和利用过去帧的信息来辅助当前帧的分割任务,从而降低内存和计算复杂度。
- 记忆交叉注意力机制:提出基于记忆空间嵌入的高效交叉注意力机制,显著减少计算和参数需求。
- 局部性利用:通过平均池化生成记忆空间嵌入的粗略表示,保持准确性同时减少计算量。
- 模型训练与优化:EfficientTAM在SA-1B和SA-V数据集上进行训练,针对视频对象分割和跟踪任务进行优化,并在多个基准上进行评估,确保模型的广泛适用性。
项目官网
- 项目官网:yformer.github.io/efficient-track-anything
- GitHub仓库:https://github.com/yformer/EfficientTAM
- HuggingFace模型库:https://huggingface.co/spaces/yunyangx/EfficientTAM
- arXiv技术论文:https://arxiv.org/pdf/2411.18933
应用场景
- 移动视频编辑:适用于智能手机等移动设备的实时视频编辑,例如分割特定对象、替换背景或进行特效处理。
- 视频监控:能够实时跟踪和分割监控视频中的对象,有助于安全监控、人流统计以及异常行为检测。
- 增强现实(AR):在AR应用中,实时识别和分割现实世界中的对象,为用户提供虚拟信息或图像叠加。
- 自动驾驶:在自动驾驶系统中,实时分析道路情况,识别和跟踪行人、车辆及其他障碍物。
- 医疗影像分析:辅助医疗影像分析,通过分割医疗影像中的关键结构,帮助医生进行诊断和治疗规划。
常见问题
- EfficientTAM适合哪些设备使用?:EfficientTAM特别优化了模型大小和计算效率,非常适合在资源受限的移动设备上使用。
- 该模型的处理速度如何?:EfficientTAM在保证高分割质量的前提下,具备快速的处理能力,适合实时视频分析。
- 如何获取EfficientTAM?:用户可以通过访问项目官网、GitHub仓库和HuggingFace模型库获取EfficientTAM的相关资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。