原标题:英伟达提出全新Star Attention,10倍加速LLM推理!登顶Hugging Face论文榜
文章来源:新智元
内容字数:4274字
引言
随着大模型上下文长度的不断增加,推理计算成本也随之上升,导致用户在输入问题后需要等待较长时间才能得到结果。为了解决这一问题,英伟达最新提出的Star Attention机制显著减少了推理计算量,同时保持了模型的精度,尤其适用于边缘计算场景。
Star Attention的工作原理
Star Attention的推理过程分为两个阶段:首先是上下文编码阶段,在此阶段,输入的上下文被分割成较小的块,并分配给多个主机处理。每个主机在处理自己的部分时,会存储非锚点部分的KV缓存。第二阶段是查询编码和token生成,查询被广播到所有主机,查询主机通过聚合所有主机的统计数据来计算全局注意力。这个方式使得在处理长序列时,信息的获取更加高效。
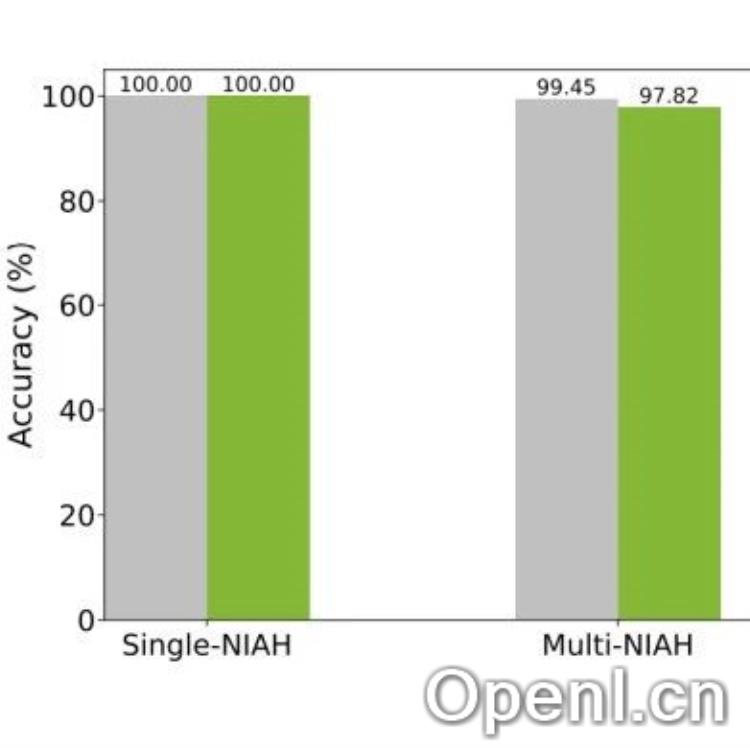
性能提升
Star Attention在多个长上下文基准测试上表现出色,推理速度最高可提升11倍。在Llama3.1-70B等大型模型上,推理加速比显著提升,同时准确率仅降低0至3%。即使在更长的上下文(例如128K和1048K)下,Star Attention依然保持了高水平的准确性和显著的加速效果。
应用前景
Star Attention的机制可以无缝集成到基于Transformer的大多数LLM中,且不需要额外的模型微调。这项技术的推出,将使得在本地设备上处理更长序列变得更加可行,同时大幅降低了内存需求。未来的研究将探索将Star Attention扩展到更长的序列和更大的模型,以进一步提高性能和可扩展性。
结论
总的来说,Star Attention为希望开发和部署本地大模型的厂商提供了一种重要技术。它不仅能加快用户响应速度,还能在有限的内存中处理更长的文本,提升RAG任务的效率。同时,对于云端大模型提供商来说,Star Attention可以显著降低推理成本,减少能源消费,从而实现更高效的模型运作。
联系作者
文章来源:新智元
作者微信:
作者简介:智能+中国主平台,致力于推动中国从互联网+迈向智能+新纪元。重点关注人工智能、机器人等前沿领域发展,关注人机融合、人工智能和机器人对人类社会与文明进化的影响,领航中国新智能时代。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。