可以把它想象成给 AI 一套复杂的规则~
强化微调(Reinforcement Fine-Tuning)简介
在当前人工智能领域,强化微调(Reinforcement Fine-Tuning,RFT)作为一种新兴的训练方法,正在吸引越来越多的关注。它不仅仅是简单的监督微调(SFT),而是通过高质量的任务数据和参来提升模型的推理能力。本文将对强化微调的原理、方法及其应用进行简要总结。
1. 强化微调的基本原理
强化微调的核心在于让模型在特定领域中通过推理学习找到正确答案。这一过程包括使用微调数据集进行训练和利用测试数据集进行验证。模型在训练阶段并不能直接看到正确答案,而是通过输出推理结果并接受评分器的评估来逐步优化其性能。
2. 训练和验证过程
强化微调的训练过程主要分为几个步骤:首先,用户准备一个训练数据集和一个验证数据集。在训练中,评分器会根据模型输出与正确答案的匹配程度打分,帮助模型调整学习策略。这一过程的反复迭代,能够显著提升模型在特定领域的准确性。
3. 应用领域及优势
强化微调尤其适用于法律、金融、医疗等有明确答案的专业领域。通过强化微调,模型在这些领域的表现能够超过传统的训练方法,展现出更强的推理和解决问题能力。OpenAI的研究表明,使用强化微调后的模型在多个指标上表现优于规模更大的基础模型。
4. 开发与用户体验
用户只需简单配置评分器和调整一些训练参数,便可以创建经过强化微调的定制模型。虽然目前OpenAI的强化微调功能处于Alpha测试阶段,但其潜力已开始显现,为专业模型训练提供了新的可能性。
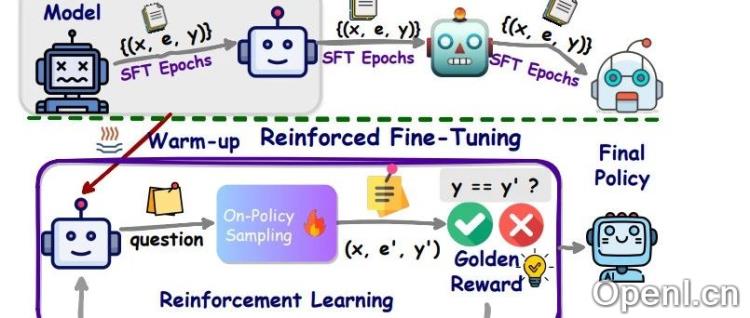
5. ReFT技术的起源与发展
强化微调的概念最早由字节跳动提出,并在ACL 2024会议上发表了相关研究论文。该技术结合了监督微调和强化学习,特别在数学问题的推理上显示出优越性。通过预热阶段和强化学习阶段的结合,ReFT在性能上超越了传统的SFT方法。
总结
强化微调作为一种新兴的技术,正在逐渐改变AI模型的训练方式。通过高质量的数据集和有效的评分机制,强化微调能够让模型在特定领域中达到更高的专业水平,为未来的AI应用开辟了新的方向。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。