通过VLM范式解决OCR任务的工作~
原标题:万字分享多模态大模型OCR工作 OCR VLM
文章来源:智猩猩GenAI
内容字数:20253字
文本OCR任务的现状与发展
随着机器学习与大语言模型(MLLM)领域的发展,文本OCR(光学字符识别)任务逐渐受到重视。传统的OCR系统通常采用多模块的pipeline设计,包括元素检测、区域裁剪和字符识别等。这一方法不仅容易导致过拟合,还增加了维护成本,且在不同场景下需要专门训练不同模型。为了应对这些挑战,许多研究者开始尝试通过视觉语言模型(VLM)来解决OCR任务。
1. OCR任务的特点
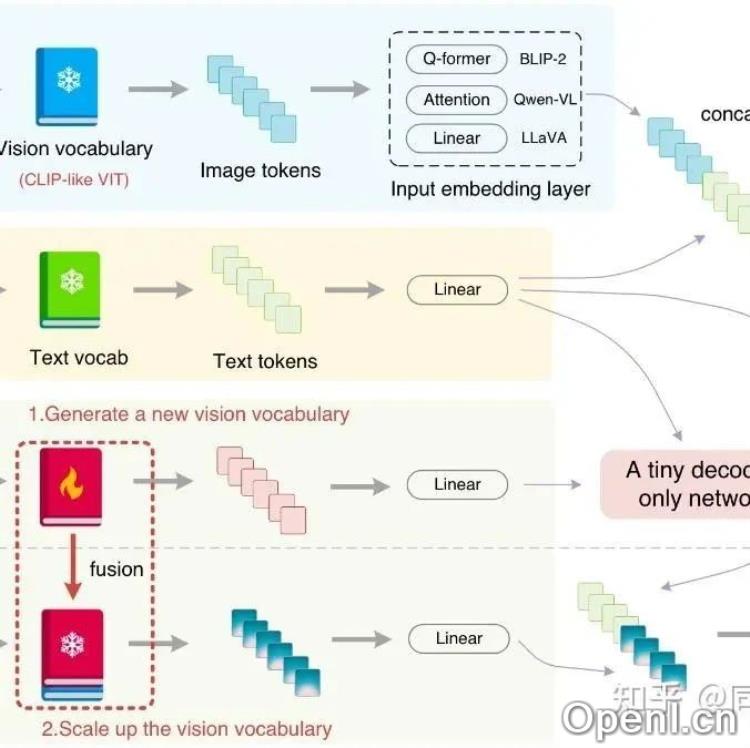
OCR任务最显著的特点是需要处理高分辨率的输入图像。图像越大,包含的字符越多,识别效果也更佳。此外,OCR任务强调感知能力,而不是复杂的推理能力,因此需要大量的视觉token支持。为了实现高效的OCR,动态分辨率和视觉token压缩方案成为了重要的研究方向。
2. 主要研究工作
在这方面,几篇关键的研究工作值得关注:
1. **GOT-OCR 2.0**:该模型旨在实现端到端的OCR解决方案,支持动态分辨率和多页OCR,且模型轻量化,使用小型视觉编码器与大语言模型相结合。其关键在于通过多阶段训练提升模型能力,并结合丰富的OCR数据集进行训练。
2. **Vary**:该研究提出了视觉词表的概念,通过构造新的ViT模型来实现OCR任务。该模型通过对比正负样本的方式,提升了对OCR场景的理解能力。
3. **TextMonkey**:该模型通过滑动窗口注意力机制和Token Resampler来提高对文本的理解,优化了输入的图像切分策略,增强了模型对文本位置信息的分析能力。
4. **mPLUG系列**:阿里巴巴的mPLUG团队开发的DocOwl系列通过统一结构学习,实现了文档理解的多任务训练,支持高分辨率的图像处理,提升了模型的通用性和精准度。
3. 未来展望
尽管当前的OCR技术已经取得了显著进展,但仍需进一步优化模型的泛化能力和适应性,以应对不同应用场景的挑战。未来的研究方向可能集中在提高模型的推理能力、增强对复杂文本结构的解析能力以及整合更多类型的视觉信息上。
总之,随着OCR技术的不断发展,结合视觉语言模型的创新方法将为OCR任务带来新机遇,推动相关领域的进一步发展。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。