产品名称:CosyVoice 2.0
产品简介:CosyVoice 2.0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升。
详细介绍:
CosyVoice 2.0是什么
CosyVoice 2.0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升,MOS评测分从5.4提升到5.53,支持流式推理,大幅降低首包合成延迟至150ms,适合实时语音合成场景。
CosyVoice 2.0的主要功能
- 超低延迟的流式语音合成:支持双向流式语音合成,首包合成延迟可达150ms,适合实时应用场景。
- 高准确度的发音:相比前版本,发音错误率显著下降,尤其在处理绕口令、多音字、生僻字上表现突出。
- 音色一致性:在零样本和跨语言语音合成中保持音色高度一致性,提升合成自然度。
- 自然体验:合成音频的韵律、音质、情感匹配得到提升,MOS评测分提高,接近商业化语音合成大模型。
- 多语言支持:在大规模多语言数据集上训练,实现跨语言的语音合成能力。
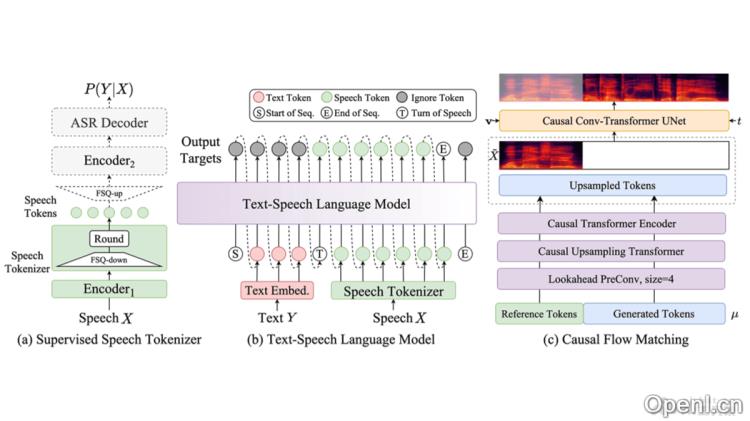
CosyVoice 2.0的技术原理
- LLM backbone:基于预训练的文本基座大模型(如Qwen2.5-0.5B),替换原有的Text Encoder + random Transformer结构,进行文本的语义建模。
- FSQ Speech Tokenizer:用全尺度量化(FSQ)替换向量量化(VQ),训练更大的码本(6561),实现100%激活,提升发音准确性。
- 离线和流式一体化建模方案:提出一体化建模方案,让LLM和FM均支持流式推理,实现快速合成首包音频。
- 指令可控的音频生成能力升级:优化基模型和指令模型的整合,支持情感、说话风格和细粒度控制指令,新增中文指令处理能力。
- 多模态大模型技术:基于多模态大模型技术,实现语音识别、语音合成、自然语言理解等AI技术,提供“能听、会说、懂你”式的智能人机交互体验。
CosyVoice 2.0的项目地址
- 项目官网:https://funaudiollm.github.io/cosyvoice2/
- GitHub仓库:https://github.com/FunAudioLLM/CosyVoice
- 技术论文:https://funaudiollm.github.io/pdf/CosyVoice_2.pdf
CosyVoice 2.0的应用场景
- 智能助手和机器人:为智能助手和机器人提供自然流畅的语音输出,提升用户体验。
- 有声读物和音频书籍:生成高质量的有声读物,支持多种语言和方言,满足不同用户的需求。
- 视频配音和解说:为视频内容提供配音服务,包括教育视频、企业宣传片、电影和电视剧的配音。
- 客户服务和呼叫中心:在客户服务中提供语音交互,提高服务效率和客户满意度。
- 语言学习和教育:辅助语言学习,提供标准发音的语音示范,帮助学习者提高发音准确性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。