产品名称:LatentLM
产品简介:LatentLM是微软研究院和清华大学共同推出的多模态生成模型,能统一处理离散数据(如文本)和连续数据(如图像、音频)。模型用变分自编码器(VAE)将连续数据编码为潜在向量,引入下一个词扩散技术自回归生成向量。
详细介绍:
LatentLM是什么
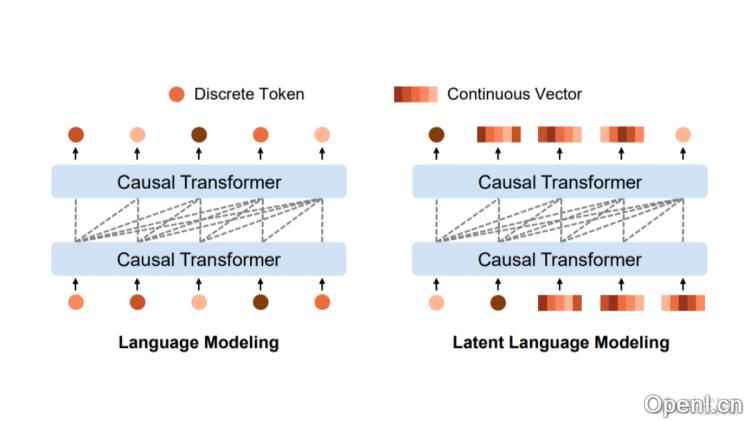
LatentLM是微软研究院和清华大学共同推出的多模态生成模型,能统一处理离散数据(如文本)和连续数据(如图像、音频)。模型用变分自编码器(VAE)将连续数据编码为潜在向量,引入下一个词扩散技术自回归生成向量。LatentLM基于因果Transformer架构实现不同模态间信息共享,提高模型在多模态任务中的性能和可扩展性。LatentLM推出σ-VAE解决方差崩溃问题,增强自回归建模的鲁棒性,在图像生成、多模态大型语言模型和文本到语音合成等多个领域展现出卓越性能。
LatentLM的主要功能
- 多模态数据处理:同时处理离散数据(如文本和代码)和连续数据(如图像、音频、视频)。
- 统一的生成与理解接口:提供一个接口,统一多模态数据的生成和理解,例如,可以生成文本、图像、音频和视频的任意组合。
- 自回归生成:基于next-token diffusion技术,模型自回归地生成连续数据的潜在向量。
- 高性能图像生成:在图像生成任务中,与基于扩散或离散标记的模型相媲美。
- 多模态大型语言模型集成:集成到多模态大型语言模型中,提升语言模型在多模态任务中的表现。
- 文本到语音合成:在文本到语音合成领域,用更少的解码步骤实现优于现有最先进模型的性能。
LatentLM的技术原理
- 变分自编码器(VAE):用VAE将连续数据编码为潜在向量,向量随后被解码器重构为原始数据。
- 下一个词扩散(Next-Token Diffusion):一种自回归生成潜在向量的方法,其中扩散头根据每个Transformer隐藏状态产生潜在向量。
- 因果Transformer:用因果Transformer处理离散和连续数据,支持模型自回归地预测序列中的下一个元素。
- σ-VAE:为解决方差崩溃问题,LatentLM提出了σ-VAE,基于在潜在空间中保持固定方差提高模型在自回归建模中的鲁棒性。
- 混合模态训练:在训练中处理不同类型的数据,包括纯文本数据、图像-文本对数据和交错的图像-文本数据。
- 高效的推理过程:在推理时,基于Transformer主干的单次传递和轻量级扩散头的多次去噪步骤,实现高效的解码过程。
LatentLM的项目地址
- GitHub仓库:https://github.com/microsoft/unilm/tree/master/LatentLM
- arXiv技术论文:https://arxiv.org/pdf/2412.08635
LatentLM的应用场景
- 图像生成:根据用户提供的文本描述自动创作出相应的图像,适用于广告设计和游戏开发中快速原型设计。
- 智能客服:在客户服务中,理解用户的自然语言查询,提供包含图像、文本和链接的多模态回答。
- 语音助手:将用户的语音指令转换成文字,提供语音回复,适用于智能家居控制和个人助理设备。
- 自动字幕生成:在视频内容中,实时生成与视频内容匹配的字幕,提高内容的可访问性。
- 虚拟主播:基于LatentLM生成的语音和图像,创建虚拟新闻主播或教学视频的虚拟讲师。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。