X-AnyLabeling是一款先进的图像标注软件,集成了多种深度学习算法,致力于显著提高标注的效率与准确性。它能够处理多种标注样式,适用于图像和视频的标注需求,覆盖多个AI训练场景,并提供图像级与对象级的标签分类。此软件支持主流深度学习框架的数据格式的导入与导出,具备良好的跨平台兼容性,同时支持CPU与GPU推理。
X-AnyLabeling是什么
X-AnyLabeling是一款集成多种深度学习算法的图像标注工具,旨在提升标注作业的效率和准确性。它支持多样化的图像和视频标注样式,适应于不同的AI训练场景,能够进行图像级和对象级的标签分类。该软件还支持主流深度学习框架的数据格式的导入与导出,并具备跨平台兼容性,能够在CPU和GPU上进行推理。最新版本X-AnyLabeling v2.5.0特别增强了小目标筛查功能,引入了基于视觉-文本提示的交互式检测与分割标注算法,适用于学术研究和工业应用中的多种视觉任务,是图像标注领域的强大利器。
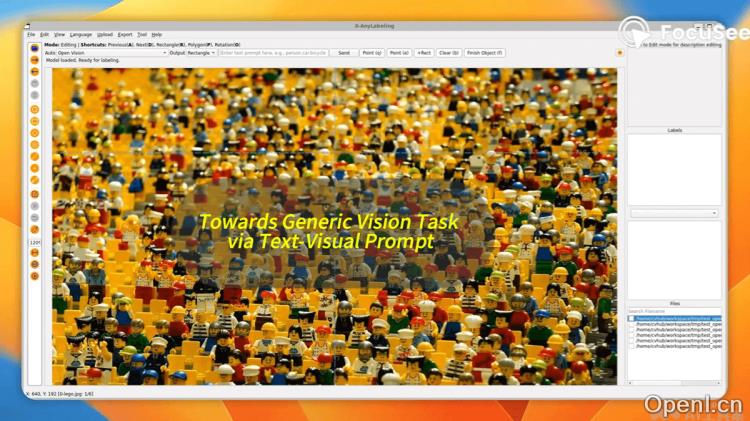
X-AnyLabeling的主要功能
- 多样化标注样式:支持多种标注形式,如矩形框、多边形、旋转框、点、线段、折线段和圆形,适合目标检测和图像分割等多种场景。
- 图像级与对象级标签分类:适用于图像分类、描述及标签等多种子任务。
- 多格式数据转换:支持YOLO、OpenMMLab、PaddlePaddle等深度学习框架的数据导入与导出。
- 跨平台与多硬件支持:可在Windows、Linux和MacOS等操作系统上运行,支持CPU和GPU的推理。
- 目标筛查功能:提供循环遍历子图的功能,以提高小目标标注的质量和效率。
- 基于视觉-文本提示的交互式检测和分割标注:新算法Open Vision结合了Visual-Text Grounding和Segment-Anything的优势。
X-AnyLabeling的技术原理
- 深度学习算法集成:集成多种深度学习模型,如YOLO系列和RT-DETR系列,以执行目标检测和图像分割等任务。
- 视觉-文本提示融合:运用Open Vision算法,将自然语言提示与视觉输入相结合,提升任务处理的智能性与直观性。
- 多模态基础模型:利用Florence 2等模型,实现视觉与语言理解的统一处理架构。
- 交互式分割技术:基于Segment Anything 2算法,提供交互式的图像分割功能。
- 跨平台框架适配:适应不同深度学习框架的数据格式,确保跨平台的数据兼容性与使用便利性。
- 硬件加速推理:通过GPU加速推理,提高模型的运行效率。
X-AnyLabeling的项目地址
X-AnyLabeling的应用场景
- 自动驾驶:用于自动驾驶系统中的车辆检测、行人识别、车道线检测和交通标志识别等,提升系统的安全性与准确性。
- 安防监控:在视频监控中进行目标检测和多目标跟踪,用于异常行为分析和人流统计。
- 医疗影像分析:基于图像分割技术,辅助医生识别和分析病变区域,提高诊断精度。
- 工业检测:在制造业中应用于产品质量检测,包括缺陷识别和异物检测等。
- 农业自动化:在精准农业中用于作物病害检测和产量评估等。
常见问题
- 如何下载和安装X-AnyLabeling?:您可以访问X-AnyLabeling的官方网站或GitHub仓库,获取最新版本的软件包和安装说明。
- 支持哪些深度学习框架?:X-AnyLabeling支持YOLO、OpenMMLab、PaddlePaddle等多个主流深度学习框架的数据格式。
- 可以在哪些操作系统上使用?:X-AnyLabeling可在Windows、Linux和MacOS等多个操作系统上运行。
- 是否支持GPU加速?:是的,X-AnyLabeling支持GPU加速推理,以提高性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。