1元钱就能处理248张图
豆包视觉理解模型的升级与应用
近日,豆包发布了其最新的视觉理解模型,带来了显著的功能提升。这一模型能够通过分析APP截图,快速生成相应的代码,极大地简化了APP开发过程。本文将对豆包的升级亮点及其在AI领域的应用进行总结。
1. 视觉理解能力的增强
豆包的视觉理解模型具备强大的内容识别能力,支持OCR、图像知识、动作情绪等多种功能,尤其在理解中国传统文化方面表现突出。此外,模型在理解与推理方面也进行了优化,提升了数学、逻辑、代码的推理能力。
2. 快速生成代码的能力
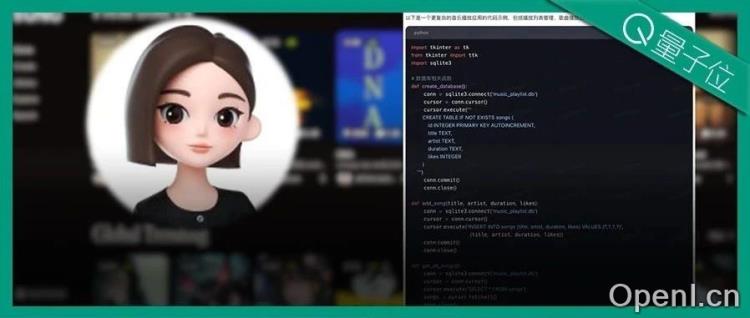
用户只需上传一张APP截图并输入简单指令,豆包便能在短时间内生成完整的代码。例如,在生成音乐APP的代码时,模型仅用时30秒便完成了基本框架,而在进一步要求下,复杂功能的实现也仅花费了1分钟。
3. 与其他大模型的对比
在与OpenAI的GPT-4o进行的多轮比拼中,豆包模型在复杂物体识别、找茬游戏、数学推理等方面表现出色,尤其在特定领域的知识理解上胜过竞争对手,显示出其独特的优势。
4. 日常实用性与行业应用
豆包的视觉模型在实际应用中展现了强大的数据提取能力,能够清晰地整理财务数据,提升了用户体验。此外,豆包已在教育、金融、医疗等多个领域落地,并与多家头部企业达成合作。
5. 未来展望与用户反馈
豆包在“说”、“唱”、“看”三大维度的提升,展现了其在AI领域的广阔前景。用户对这些新功能的反馈将进一步推动模型的优化和发展,期待更多的创新应用。随着技术的不断进步,豆包的未来可期。
总之,豆包的视觉理解模型有效地提升了APP开发的效率,并在多领域展现出强大的应用潜力。用户可以期待在未来的互动中获得更好的体验。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。