本文整理工业界主流开源LLM的后训练方案,着重介绍训练算法和数据处理部分。
原标题:工业界主流大语言模型后训练(Post-Training)技术总结
文章来源:智猩猩GenAI
内容字数:66914字
文章要点总结
本文主要讨论了多款大语言模型(LLM)的后训练方案,包括Llama3、Qwen2、Nemotron、AFM等,重点在于各自的训练算法和数据处理方法。随着工业界对大语言模型的开源,技术报告也逐渐丰富,本文整理了相关的后训练策略,以帮助企业在竞争中保持领先。
数据合成与偏好数据构造
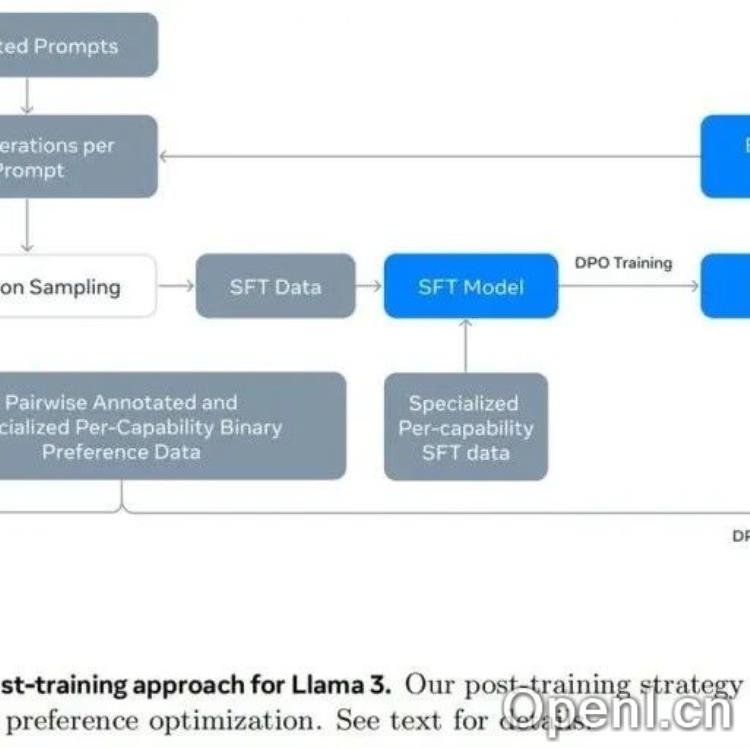
数据合成已成为后训练的主流方案,模型如Llama3和Qwen2均采用拒绝采样技术,通过多次采样和人类评估构造偏好样本对。此外,使用不同规模模型的输出也增强了数据多样性。
强化学习策略
在强化学习方面,Llama3和Qwen2均使用了改良版的直接偏好优化(DPO),并未采用传统的PPO方法。不同模型的强化学习技术各有不同,Nemotron则采用了多属性回归奖励模型,以提升模型的有用性预测能力。
模型合并与能力优化
模型合并技术被广泛应用,例如Llama3和Gemma2,通过训练不同版本的数据以实现更均衡的性能。此外,模型在特定能力上(如代码、数学推理)进行单独优化,以提升整体表现。
数据质量与处理
数据的质量控制至关重要,各模型都实施了严格的数据清洗和质量检测措施。通过自动化的质量评估机制,确保训练数据的高标准,进而提高模型的生成能力和准确性。
多语言与工具使用能力
在多语言能力的提升上,模型通过多语言数据集的采集与训练,优化了多语言理解和生成。此外,针对工具使用能力的训练,模型通过模拟不同场景,增强了其对各种工具的使用和协调能力。
综上所述,本文通过对各大模型的后训练方案进行分析,揭示了数据合成、偏好构造、强化学习及数据处理等方面的最新进展,为相关领域的研究和应用提供了重要参考。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。