在这里做一个简单的code walkthroug,以release的0.5.3版本为基准。
原标题:如何基于 OpenRLHF 定制内部 RFT 训练框架
文章来源:智猩猩GenAI
内容字数:3218字
第四届全球自动驾驶峰会及OpenRLHF框架解读
本文首先简要介绍了将于1月14日在北京举办的第四届全球自动驾驶峰会,并列举了部分已确认参会的嘉宾及峰会日程安排。随后,文章重点关注如何将强化学习融入AI训练框架,特别是针对LLM+RL的训练。
强化学习在AI训练框架中的挑战
1. **多模型协调与通信:** RL算法(如PPO、Reinforce)通常涉及多个模型间的协作,其通信方式与传统的预训练/微调(pretrain/SFT)中的MPI集合通信有所不同,增加了实现难度。
2. **参数调优的复杂性:** RL算法参数众多,对精度要求高,缺乏RL经验的工程师难以判断训练失败是框架问题还是超参数问题。
OpenRLHF框架的优势及推荐
文章推荐使用OpenRLHF框架进行LLM+RL训练,并阐述了其优势:
1. **基于Ray的多模型调度:** 支持任意扩展每个模型的GPU数量,提高可扩展性。
2. **模块化设计:** 训练和推理模块分离,方便替换和定制。
3. **高可靠性和优秀的默认超参数:** 经过大量验证,默认超参数表现出色,减少了调参的工作量。
4. **轻量级和易读性:** 代码简洁易懂,方便二次开发。
5. **功能全面:** 支持主流的LLM+RL算法(PPO、Reinforce)以及关键优化功能,例如打包样本(packing samples)。
文章建议将现有RL训练框架中的LLM部分替换成自己的框架,并复用OpenRLHF的多模型调度机制,从而实现事半功倍的效果。
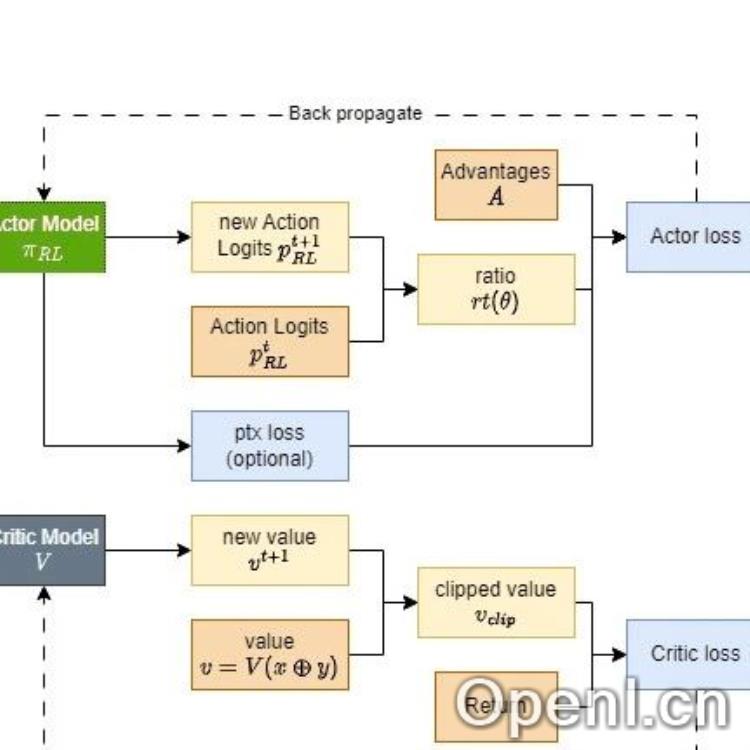
OpenRLHF框架代码解读
文章对OpenRLHF框架的关键文件进行了简要分析:
1. openrlhf/cli/train_ppo_ray.py: 训练入口,包含配置项和模型初始化。
2. openrlhf/trainer/ppo_trainer.py: 包含PPO训练的基本流程,包括rollout生成和模型训练。
3. openrlhf/trainer/ppo_utils/experience_maker.py: 生成rollout数据,包括调用VLLM和计算logprob、KL、reward等。
4. openrlhf/trainer/ray/ppo_actor.py: Ray版本的PPOTrainer,包含通信同步逻辑。
5. openrlhf/utils/deepspeed/deepspeed.py: 进行deepspeed初始化,需要替换deepspeed时需关注此文件。
实现OpenAI RFT可能遇到的问题及解决方法
文章还指出了在使用OpenRLHF实现OpenAI RFT时可能遇到的问题以及相应的解决方法:
1. **Verifier接入:** 使用remote_rm_url接入Verifier,参考openrlhf/cli/serve_rm.py。
2. **数据多样性:** 通过--n_samples_per_prompt参数设置每个问题采样多个回答。
3. **Critic模型缺失:** 使用--freezing_actor_steps预训练Critic,或使用无需Critic的算法(Reinforce、RLOO)。
4. **Reward后处理:** 在process_experiences方法中注册自定义的处理方法。
总而言之,文章推荐OpenRLHF框架作为LLM+RL训练的理想选择,并提供了详细的代码解读和问题解决方法,方便工程师进行二次开发和应用。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。