ModernBERT – 英伟达和 HuggingFace 等机构联合开源的新一代编码器模型
ModernBERT:下一代自然语言处理模型的革新
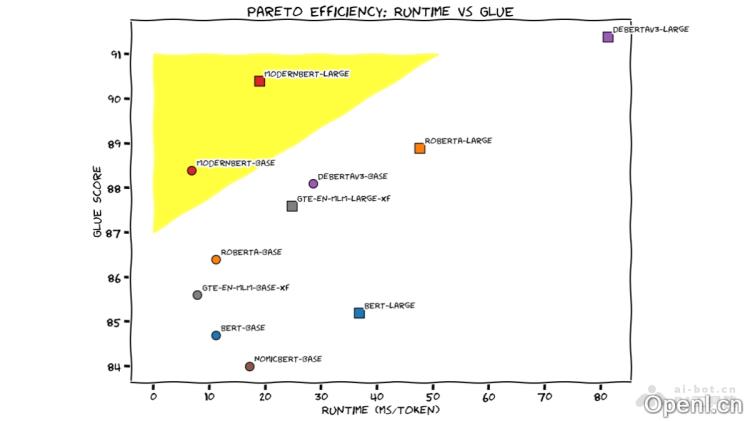
ModernBERT是由Answer.AI、LightOn、约翰斯·霍普金斯大学、英伟达和HuggingFace共同开发的先进编码器-only Transformer模型,代表了经典BERT模型的一次重要演进。该模型经过在2万亿token的大规模数据集上训练,支持最长8192 token的序列,有效提升了长文本处理的能力。在多项自然语言处理任务中,ModernBERT的表现优于现有最先进技术(SOTA),且速度是DeBERTa的两倍,特别适合信息检索、文本分类和实体识别等应用。现已开源,供学术界和工业界进行研究与应用。
ModernBERT是什么
ModernBERT是一个现代化的编码器-only Transformer模型,旨在改进和扩展经典BERT的能力。通过在极大规模的数据集上进行训练,ModernBERT能够处理更长的上下文信息,从而满足复杂自然语言处理的需求。
主要功能
- 长文本处理能力:支持最长8192 token的序列,大幅提升对长文本的理解和处理能力。
- 高效的信息检索:在语义搜索和文档检索中,ModernBERT能够更好地表示文档和查询,从而提高检索的准确性。
- 快速文本分类:在情感分析和内容审核等任务中,能够迅速准确地进行文本分类。
- 精准实体识别:在自然实体识别任务中,有效识别文本中的特定实体。
- 代码信息检索:在编程语言相关的应用中表现出色,能够有效处理和检索大量代码信息。
- 性能优化:在保持高效能的同时,优化速度和内存使用,使模型更加高效。
产品官网
- GitHub仓库:https://github.com/AnswerDotAI/ModernBERT
- HuggingFace模型库:https://huggingface.co/collections/answerdotai/modernbert
- arXiv技术论文:https://arxiv.org/pdf/2412.13663
应用场景
- 语义搜索与信息检索:构建更精准的搜索引擎,理解用户查询的语义,从而提供更相关的结果。
- 内容推荐系统:在推荐系统中,深入理解用户兴趣与内容语义,推荐更符合用户偏好的信息。
- 自然语言理解任务:涵盖情感分析、意图识别、语言推理等,提供更深层次的语言理解能力。
- 文本分类:对新闻文章、客户反馈、社交媒体帖子等进行分类,方便内容管理和分析。
- 问答系统:在问答系统中,理解复杂问题并从大量文档中检索出正确答案。
常见问题
- ModernBERT与BERT有何不同? ModernBERT在架构、训练数据和处理能力上进行了显著改进,特别是在长文本处理方面。
- 如何开始使用ModernBERT? 用户可以通过GitHub仓库获取模型,并参考文档进行部署和使用。
- ModernBERT适合哪些应用? 该模型适用于信息检索、文本分类、实体识别等多个自然语言处理任务。
- 是否有相关的技术支持? 用户可以通过GitHub提出问题或查看文档获取支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。