DeepSeek-V3出技术报告了。
原标题:国产大模型DeepSeek-V3一夜火爆全球,671B的MoE,训练成本仅558万美元
文章来源:智猩猩GenAI
内容字数:5965字
国产大模型DeepSeek-V3惊艳全球
本文概述了国产大模型DeepSeek-V3的惊人性能及其背后的技术创新,并简要介绍了即将在北京举办的第四届全球自动驾驶峰会。
1. DeepSeek-V3:高效、强大的开源大模型
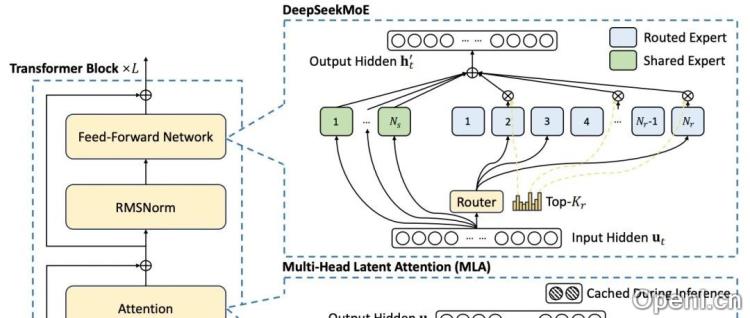
参数量高达671B的DeepSeek-V3,其预训练过程仅耗费278.8万H800 GPU小时,远低于其他同级别模型。尽管训练成本低,其性能却足以比肩甚至超越GPT-4o和Claude 3.5 Sonnet等闭源模型,尤其在数学和代码任务上表现突出。这一突破主要归功于其采用的MLA(多头隐注意力)和DeepSeekMoE架构,以及无辅助损失的负载平衡策略和多token预测训练目标等技术创新。
2. DeepSeek-V3的技术细节
为了实现高效推理和经济训练,DeepSeek-V3采用了MLA和DeepSeekMoE架构。 它还引入了多token预测(MTP)训练目标,以提高性能。与DeepSeek-V2相比,DeepSeek-V3在DeepSeekMoE中增加了辅助无损耗负载平衡策略,以提升效率。预训练数据包含14.8万亿高质量token,并经过监督式微调和强化学习。模型的Transformer层数为61,隐藏层维度为7168,使用了128个注意力头,每个头维度为128。通过两阶段扩展训练,DeepSeek-V3能够处理长达128K的输入。
3. DeepSeek-V3的性能评估
DeepSeek-V3在多个基准测试中全面超越了DeepSeek-V2、Qwen2.5 72B Base和LLaMA-3.1 405B Base等开源模型,成为目前最强大的开源模型之一。尤其在英语、代码、数学和多语言任务上表现出色。其在AGIEval、CMath、MMMLU-non-English等任务上的表现甚至远远超过其他开源大模型。
4. 业界对DeepSeek-V3的评价
Meta AI研究科学家田渊栋、著名AI科学家Andrej Karpathy以及正在创业的著名研究者贾扬清都对DeepSeek-V3给予了高度评价,认为其在资源有限的情况下取得了卓越的成果,并标志着分布式推理时代的到来。
5. DeepSeek-V3的影响
DeepSeek-V3的开源发布迅速引发了广泛关注,其在OpenRouter平台上的使用量已翻了三倍。用户们纷纷分享其使用体验,再次点燃了人们对开源模型的热情。
6. 第四届全球自动驾驶峰会
文章开头提到,1月14日,第四届全球自动驾驶峰会将在北京举办。峰会将涵盖自动驾驶领域的多个主题,包括端到端自动驾驶创新、城市NOA、自动驾驶视觉语言模型和自动驾驶世界模型等,多位业内专家将进行主题分享。
总而言之,DeepSeek-V3凭借其高效的训练和强大的性能,在人工智能领域取得了重大突破,并为开源大模型的发展树立了新的标杆。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。