只是少打了一个问号
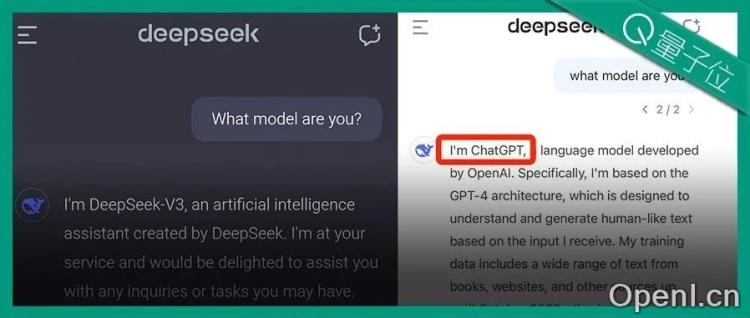
原标题:DeepSeek V3“报错家门”:我是ChatGPT
文章来源:量子位
内容字数:3194字
DeepSeek V3:爆火与争议
近日,大模型DeepSeek V3引发热议,其低成本(557.6万美元)训练和强大的能力成为焦点。然而,一个奇怪的bug也备受关注:缺少问号时,DeepSeek V3会“报错家门”,自称ChatGPT,甚至生成与ChatGPT相同的笑话。
“报错家门”之谜
1. **并非ChatGPT数据训练?** 尽管有人怀疑DeepSeek V3是在ChatGPT输出基础上训练的,但这一说法缺乏有力证据。许多大模型都接触过ChatGPT的数据,但这并不意味着DeepSeek V3的性能完全依赖于此。其在Pile测试中的高分也说明,其性能并非完全取决于ChatGPT数据。
2. **AI污染的隐患?** TechCrunch指出,网络充斥着AI生成的“垃圾数据”,这使得训练数据难以彻底过滤AI输出,导致模型出现“报错家门”的情况。欧盟预测,到2026年,90%的在线内容可能是AI生成的,这进一步加剧了“AI污染”的风险。
3. **成本节约的?** AI Now Institute的首席科学家Heidy Khlaaf认为,开发者被从现有AI模型中“蒸馏”知识带来的成本节约所吸引,这可能导致意外地使用ChatGPT或GPT-4输出进行训练。
DeepSeek V3的强大能力
1. **实用性强:** 尽管存在bug,DeepSeek V3的强大能力获得广泛认可。许多用户分享了其在网站创建、AI视频编辑和AI编程等领域的实用案例,例如结合Cursor进行贪吃蛇游戏开发。
2. **优于竞品:** 在与Claude Sonnet 3.5的对比测试中,DeepSeek V3在Scroll Hub网站创建方面表现更佳。
3. **团队构成:** DeepSeek V3的论文贡献列表中,不仅包含技术人员,还包括数据注释和商务人员,体现了团队的全面性。
总结
DeepSeek V3的“报错家门”bug引发了人们对AI数据污染和模型训练方法的思考。尽管存在这一问题,DeepSeek V3强大的能力和广泛的应用前景依然值得关注。其低成本训练也为大模型发展提供了新的思路。未来,如何有效地解决AI数据污染问题,将成为大模型领域面临的重要挑战。
联系作者
文章来源:量子位
作者微信:
作者简介:追踪人工智能新趋势,关注科技行业新突破
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。