VITRON – Skywork AI 联合新加坡国立、南洋理工推出的像素级视觉大型语言模型
VITRON是什么
VITRON是由Skywork AI、新加坡国立大学和南洋理工大合开发的一款像素级视觉大型语言模型(LLM),具备全面理解和处理静态图像与动态视频的能力。该模型能够实现对图像和视频的理解、生成、分割和编辑等多种功能。VITRON结合了前端的视觉编码器与后端的视觉专家系统,支持从视觉理解到视觉生成的多项任务。通过混合方法的信息传递,VITRON结合离散文本指令和连续信号嵌入,确保功能调用的精确性,并设计了跨任务协同模块,增强不同视觉任务之间的协作效果。
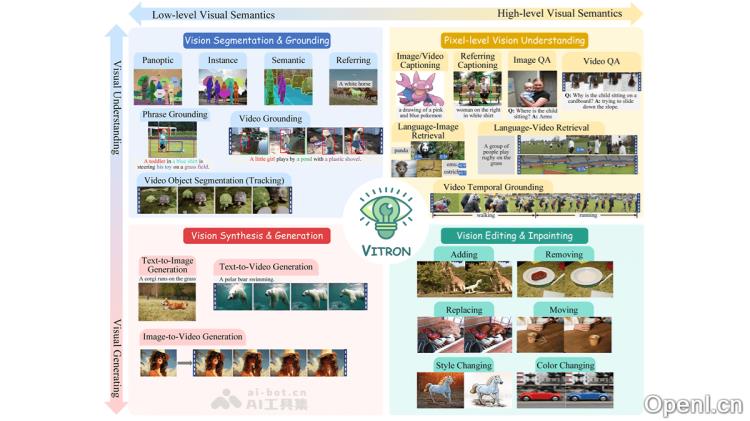
VITRON的主要功能
- 视觉理解:包括图像和视频的问答、指代表达和视觉推理等任务。
- 视觉生成:支持从文本生成图像和视频的功能。
- 视觉分割:涉及图像和视频的分割任务,例如实例分割和全景分割。
- 视觉编辑:允许对图像和视频进行编辑,包括添加、替换、移除和颜色调整等操作。
- 交互式用户输入:能够处理用户的点击、框选、绘制多边形和涂鸦等互动输入。
VITRON的技术原理
- 编码器-LLM-解码器架构:采用常见的编码器-大型语言模型(LLM)-解码器结构,编码器负责处理图像和视频输入,LLM进行语义理解与决策,而解码器则执行具体的视觉任务。
- 前端视觉-语言编码:使用CLIP ViT-L/14@336px作为图像和视频的编码器,针对每一帧视频进行平均池化,获取整体的时间特征表示。区域像素感知视觉提取器则作为草图编码器,处理用户的交互输入。
- 核心LLM:选用Vicuna(7B,版本1.5)作为核心LLM,处理来自语言和视觉模态的输入,执行语义理解和推理,生成决策。
- 后端视觉专家:集成多个单一视觉专家,包括GLIGEN(用于图像生成和编辑)、SEEM(用于图像和视频分割)、ZeroScope和I2VGen-XL(用于文本到视频和图像到视频任务)、StableVideo(用于视频编辑)等。
- 混合方法指令传递:推出了一种创新的混合方式,基于离散文本指令和连续信号特征嵌入,确保LLM的决策能够准确地传递给后端模块。
VITRON的项目地址
- 项目官网:vitron-llm.github.io
- GitHub仓库:https://github.com/SkyworkAI/Vitron
- arXiv技术论文:https://arxiv.org/pdf/2412.19806
VITRON的应用场景
- 图像编辑辅助:可用于照片修复与美化,例如去除不需要的物体或增强图像的色彩效果。
- 视频内容创作:能够根据剧本文本生成视频内容,包括场景构建和角色动画。
- 在线教育平台:在教育平台上自动生成教学视频和图像,以支持教学活动。
- 电子商务视觉营销:为电商平台自动生成商品展示视频,以提升商品的吸引力。
- 新闻媒体内容制作:帮助新闻机构快速生成新闻的视觉报道,包括图像和视频。
常见问题
- VITRON支持哪些类型的输入? VITRON可以处理静态图像和动态视频,同时支持用户的交互式输入。
- 如何访问VITRON的功能? 用户可以通过VITRON的官网或GitHub仓库获取相关信息和使用指南。
- VITRON的主要应用领域有哪些? VITRON广泛应用于图像编辑、视频内容创作、在线教育、电子商务和新闻媒体等领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。