TANGOFLUX – 英伟达联合新加坡科技设计大学开源的文本到音频生成模型
TANGOFLUX是什么
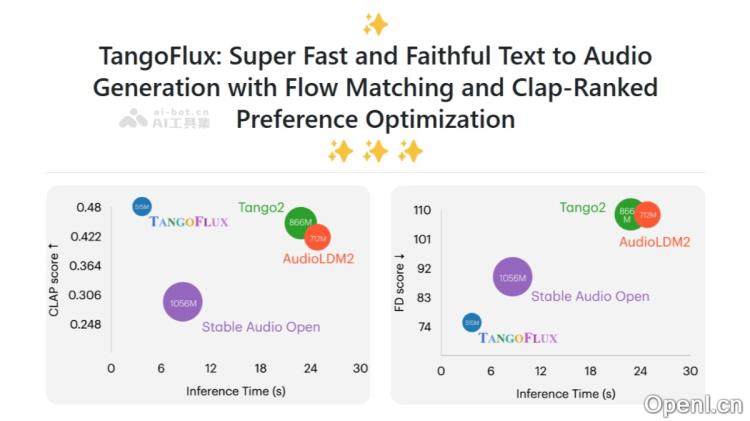
TANGOFLUX是一款高效的文本转音频生成模型,由新加坡科技设计大学(SUTD)与NVIDIA联合开发。该模型拥有约5.15亿个参数,能够在单个A40 GPU上,在仅需3.7秒的时间内生成时长最长可达30秒的44.1kHz音频。TANGOFLUX采用了CLAP-Ranked Preference Optimization(CRPO)框架,通过迭代生成和优化偏好数据,提升了模型在音频对齐方面的能力。其在多项客观和主观基准测试中表现卓越,并已在GitHub等平台上开源代码和模型,便于进一步研究。
TANGOFLUX的主要功能
- 高效音频生成:TANGOFLUX能够迅速生成高质量音频内容,仅需3.7秒即可产生长达30秒的44.1kHz音频。
- 文本到音频转换:该模型可以直接将文本描述转换为相应的音频输出,实现文本与音频的无缝连接。
- 偏好优化:TANGOFLUX能够根据用户偏好和输入文本的意图优化音频输出,提高匹配度。
- 非专有数据训练:模型基于非专有数据集进行训练,使其更加开放和可获取。
TANGOFLUX的技术原理
- 变分自编码器:通过VAE将音频波形编码为潜在表示,并从中重构原始音频。
- 文本和时长嵌入:模型利用文本编码和时长编码来控制生成音频的内容及时长,实现音频生成的可控性。
- FluxTransformer架构:构建于FluxTransformer模块之上,结合了Diffusion Transformer (DiT) 和 Multimodal Diffusion Transformer (MMDiT),以处理文本提示并生成音频。
- 流匹配(Flow Matching, FM):采用流匹配框架,学习从简单的先验分布到复杂目标分布的映射,生成样本。
- CLAP-Ranked Preference Optimization (CRPO):CRPO框架通过迭代生成偏好数据对,优化音频与文本的对齐。利用CLAP模型作为代理奖励模型,基于文本和音频的联合嵌入评估音频输出的质量,构建偏好数据集以进行优化。
- 直接偏好优化:TANGOFLUX将直接偏好优化(DPO)应用于流匹配,比较成功与失败的音频样本,从而提升模型的音频与文本描述的对齐度。
TANGOFLUX的项目地址
- 项目官网:tangoflux.github.io
- GitHub仓库:https://github.com/declare-lab/TangoFlux
- HuggingFace模型库:https://huggingface.co/declare-lab/TangoFlux
- arXiv技术论文:https://export.arxiv.org/pdf/2412.21037
- 在线体验Demo:https://huggingface.co/spaces/declare-lab/TangoFlux
TANGOFLUX的应用场景
- 多媒体内容创作:在电影、游戏、广告及视频制作中,TANGOFLUX可用于生成背景音乐、音效和配音,显著提升制作效率并降低成本。
- 音频制作与设计:音乐制作人和声音设计师可利用该模型创作新的音乐作品或设计特定音效。
- 播客与有声书:为播客或有声书自动生成背景音乐和音效,增强听众的听觉体验。
- 教育与培训:在教育领域,TANGOFLUX可用于创建模拟真实场景的音频,辅助语言学习或专业技能训练。
- 虚拟助手与机器人:为虚拟助手和机器人提供更加自然且丰富的语音反馈,提升用户的互动体验。
常见问题
- Q: TANGOFLUX是否适用于所有类型的文本?
A: 是的,TANGOFLUX能够处理多种类的文本输入并生成相应的音频输出。 - Q: 我可以在本地运行TANGOFLUX吗?
A: 是的,您可以通过GitHub上的开源代码在本地环境中运行TANGOFLUX。 - Q: TANGOFLUX支持哪些语言?
A: 目前,TANGOFLUX主要支持多种主要语言的文本生成,具体取决于训练数据的覆盖范围。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。