RLCM – 康奈尔大学推出的优化文本到图像一致性模型的框架
RLCM是什么
RLCM(Reinforcement Learning for Consistency Model)是由康奈尔大学研发的一种框架,旨在优化文本到图像生成的过程。它采用强化学习技术,针对特定任务的奖励函数对一致性模型进行微调。通过将一致性模型的多步推理过程建模为马尔可夫决策过程(MDP),并运用策略梯度算法优化模型参数,RLCM可以有效地最大化与任务相关的奖励。与传统的扩散模型相比,RLCM不仅在训练和推理速度上显著提升,还能够生成高质量的图像,尤其在处理难以用简单提示表达的目标时表现出色,例如图像的美学质量和压缩性等。
RLCM的主要功能
- 任务特定奖励优化:依据特定任务的奖励函数调整一致性模型,使生成的图像更加符合任务目标,例如提升图像的美学质量和压缩性。
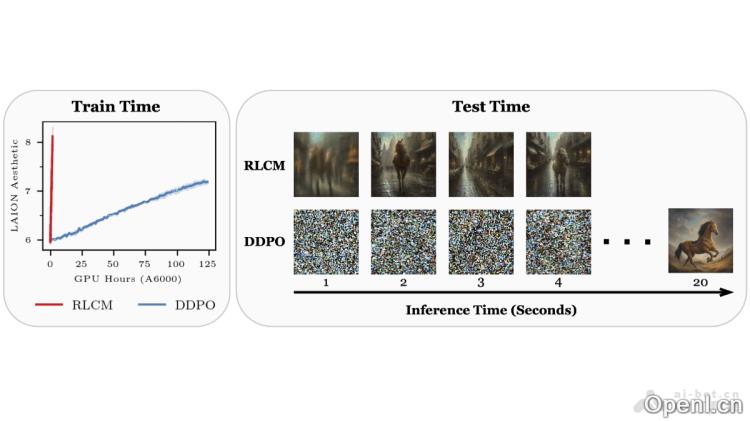
- 快速训练与推理:与传统扩散模型相比,RLCM在训练和推理速度上更为迅速,显著降低计算资源的需求,从而提高生成效率。
- 适应复杂目标:能够处理那些难以用简易提示表达的复杂目标,例如基于人类反馈的美学标准,确保生成的图像更贴近人类的审美需求。
- 灵活的推理步数调整:支持在推理速度和生成质量之间进行灵活的权衡,用户可以根据实际需求调整推理步数,以获得更快的推理速度或更高质量的图像。
RLCM的技术原理
- 一致性模型基础:基于一致性模型,该模型通过直接将噪声映射到数据,在较少的步骤内生成高质量图像,相较于扩散模型的多步迭代过程,推理速度更快。
- 强化学习框架:将一致性模型的多步推理过程视为马尔可夫决策过程(MDP),在生成过程中的每一步均为决策点,通过强化学习方法优化模型策略,旨在最大化与任务相关的奖励函数。
- 策略梯度算法:采用策略梯度算法对一致性模型进行优化,该算法基于采样策略生成的轨迹,计算策略的梯度并依据此更新模型参数,实现对奖励函数的优化。
- 奖励函数驱动:通过特定任务的奖励函数驱动,利用强化学习不断调整模型生成策略,使生成的图像更符合任务目标,从而实现高质量的图像生成。
RLCM的项目地址
- 项目官网:rlcm.owenoertell.com
- GitHub仓库:https://github.com/Owen-Oertell/rlcm
- arXiv技术论文:https://arxiv.org/pdf/2404.03673
RLCM的应用场景
- 艺术创作:艺术家可以利用RLCM探索新的绘画风格,生成符合特定风格的艺术作品,从而快速激发灵感和创作方向。
- 个性化推荐:在社交媒体平台上,用户能够生成与其个性相符的图像,提升个性化体验并增强平台的用户粘性。
- 数据集扩充:研究人员在开发自动驾驶系统时,可以生成各种天气条件、不同时间段及复杂交通情况下的模拟图像,以扩充训练数据集,提高自动驾驶模型的鲁棒性及准确性。
- 图像修复与重建:用户可以生成修复后的完整历史照片,以帮助恢复珍贵的历史记忆。
- 生物医学成像:生物医学研究人员可以模拟细胞在不同药物作用下的形态变化,依据已知的细胞形态和药物机制生成模拟细胞图像,为药物筛选和生物医学研究提供支持。
常见问题
- RLCM的主要优势是什么? RLCM通过强化学习优化一致性模型,显著提高图像生成速度和质量,特别适合处理复杂的任务目标。
- 如何开始使用RLCM? 您可以访问RLCM的官方网站或GitHub仓库,获取相关文档和代码示例,快速上手使用。
- RLCM适合哪些应用场景? RLCM广泛适用于艺术创作、个性化推荐、数据集扩充、图像修复以及生物医学成像等多种领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。