VideoRAG – 用于长视频理解的检索增强生成技术
VideoRAG是一项专为长视频理解而设计的检索增强生成(Retrieval-Augmented Generation)技术,旨在提升大型视频语言模型(LVLMs)对长视频内容的解析和处理能力。通过从视频中提取视觉对齐的辅助文本,VideoRAG能够显著改善模型的响应质量。
VideoRAG是什么
VideoRAG是一种创新的检索增强生成(RAG)技术,专注于长视频理解。它通过提取视频中的视觉对齐辅助文本,帮助大型视频语言模型(LVLMs)更有效地分析和处理长视频内容。具体而言,VideoRAG利用开源工具从视频中提取音频、文字及对象检测等信息,并将这些数据与视频帧和用户查询相结合,输入到现有的LVLM中。这种方法具有较低的计算开销,便于实现,并且能够与任何LVLM无缝兼容。在多个长视频理解的基准测试中,VideoRAG展现出显著的性能提升。
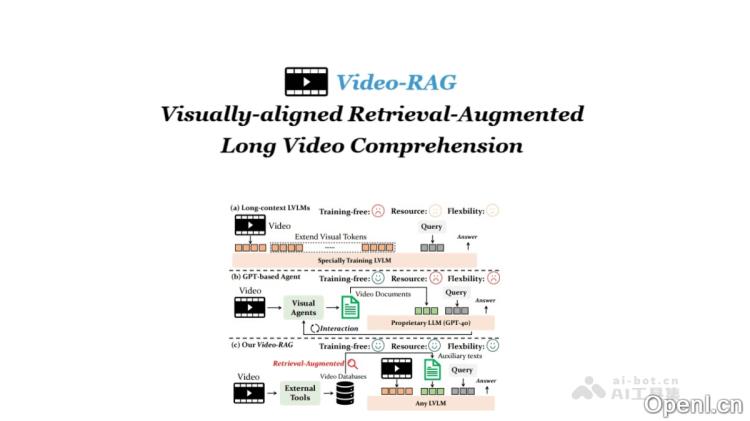
VideoRAG的主要功能
- 检索增强生成:VideoRAG通过检索与用户查询相关的辅助文本,提升模型的理解与生成能力。
- 多模态信息提取:依托开源工具(如EasyOCR、Whisper和APE),VideoRAG从视频中提取多种辅助文本类型,包括光学字符识别(OCR)、自动语音识别(ASR)和对象检测(DET)信息。
- 轻量级与高效性:VideoRAG采用单次检索的方式,具备轻量和低计算开销的特点,易于与现有大型视频语言模型(LVLMs)进行集成。
VideoRAG的技术原理
- 辅助文本提取:通过开源工具从视频中提取多种辅助文本信息,包括OCR、ASR和DET等,生成与视频帧对齐的文本描述。
- 检索模块:将提取的辅助文本存储于向量数据库中,利用检索技术找到与用户查询最相关的文本片段。这是通过将用户查询和视频内容的特征向量与数据库中的文本向量进行匹配来实现的。
- 生成模块:将检索到的辅助文本与视频帧和用户查询共同输入到已有的LVLM中,模型基于这些信息生成对用户查询的响应,辅助文本提供了额外的上下文信息,从而提升模型对视频内容的理解和生成能力。
- 跨模态对齐:通过引入辅助文本,VideoRAG促进了视频帧与用户查询之间的跨模态对齐,使模型能够更精准地关注与查询相关的关键帧。
VideoRAG的项目地址
- 项目官网:https://video-rag.github.io
- Github仓库:https://github.com/Leon1207/Video-RAG-master
- arXiv技术论文:https://arxiv.org/pdf/2411.13093
VideoRAG的应用场景
- 视频问答系统:VideoRAG可用于构建视频问答系统,使用户能够针对长视频内容提问并获得准确的回答。
- 视频内容分析与理解:在需要深入分析与理解长视频内容的场合,VideoRAG能够辅助识别和解释视频中的关键信息。
- 教育与培训:在教育领域,VideoRAG可以帮助学生和教师更好地理解和分析教学视频内容,教师也能利用VideoRAG分析教学视频以优化教学内容。
- 娱乐与媒体内容创作:在娱乐和媒体行业,VideoRAG能够加速视频内容的创作与编辑,帮助创作者迅速找到与主题相关的片段与信息,从而提高创作效率。
- 企业内部知识管理:企业可利用VideoRAG对内部培训视频和会议记录等长视频内容进行有效管理与检索,方便员工快速获取所需信息,提升工作效率。
常见问题
- VideoRAG的兼容性如何? VideoRAG设计为与任何大型视频语言模型(LVLMs)兼容,便于集成使用。
- 使用VideoRAG需要什么样的技术基础? 用户只需具备基本的编程知识和对开源工具的了解,即可上手VideoRAG的使用。
- VideoRAG能否处理实时视频? 当前版本主要针对长视频内容,实时视频处理的功能正在研发中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...


打开我,进入AI时代。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。
全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。