原标题:华佗GPT-o1:医疗大模型在复杂推理上的重大突破
文章来源:小夏聊AIGC
内容字数:2337字
HuatuoGPT-o1:医疗AI复杂推理能力的里程碑
人工智能在医疗领域的应用日益深入,而复杂推理能力一直是制约医疗AI发展的瓶颈。近日,香港中文大学(深圳)与深圳大数据研究院的研究团队突破性地推出了HuatuoGPT-o1,一款专注于医疗领域的超大型语言模型(LLM),它在复杂医疗推理能力上取得了显著进展,为医疗诊断和决策提供了更可靠的支持。
突破性的训练方法
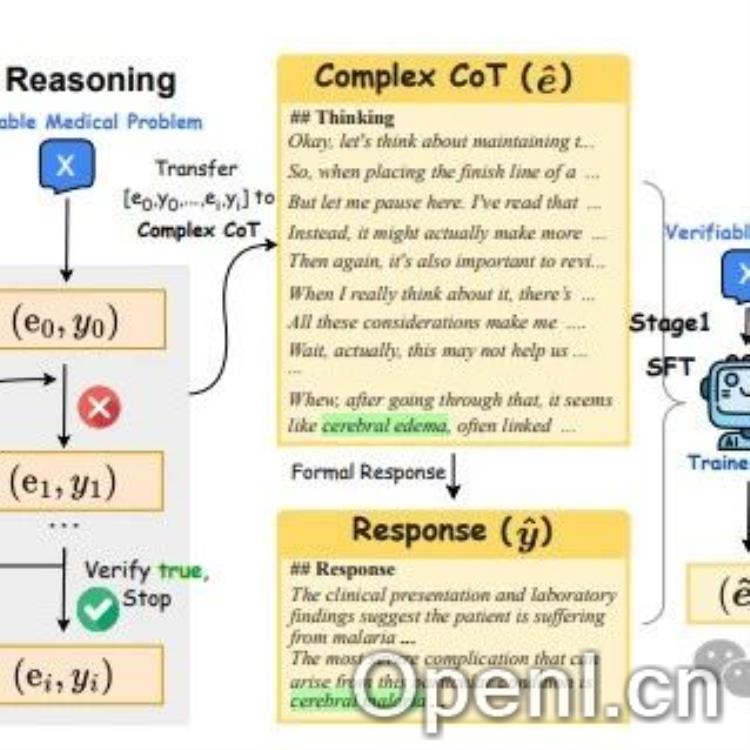
HuatuoGPT-o1的成功并非偶然,其核心在于创新的两阶段训练方法。第一阶段,研究团队巧妙地利用了4万道来自医疗考试题库的难题,将其转化为开放式问题,构建了一个可验证的医疗问题集。模型通过基于策略的搜索,生成复杂的推理轨迹,并利用验证器(GPT-4o)的反馈进行迭代修正,直到找到正确答案。这一过程类似于医生在诊断过程中反复思考、验证和修正的过程。成功的推理轨迹则被用来微调LLM,使其学习到更严谨的思维模式。
第二阶段,研究团队则采用强化学习(RL)算法,利用验证器提供的稀疏奖励进一步提升模型的推理能力。这种强化学习机制,让模型能够在不断尝试和纠错中,不断优化其推理策略,最终达到更高的准确率。
卓越的性能与可靠性
实验结果令人振奋。一个参数量仅为80亿的HuatuoGPT-o1模型,在医疗基准测试中就取得了8.5分的显著提升。而参数量达到700亿的模型,更是超越了其他开源的通用及医疗专用LLM。这充分证明了HuatuoGPT-o1在复杂医疗推理方面的卓越性能。
为了确保模型的可靠性,研究团队使用了GPT-4o作为验证器,结果显示其在两个阶段的准确率分别达到了96.5%和94.5%。此外,研究还证实了基于LLM的验证器比传统的精确匹配方法更可靠,并且该方法在中文医疗领域也取得了显著成果,展现了其良好的适应性。
独特的创新之处与未来展望
HuatuoGPT-o1的创新之处在于它首次采用了可验证的医疗问题和医疗验证器来提升LLM的医疗复杂推理能力。这使得模型能够进行更深入的思考,并在给出答案之前进行自我检查和修正,如同一位经验丰富的医生一样。这种方法不仅提高了模型在医疗领域的应用潜力,也为其他专业领域推理能力的提升提供了宝贵的经验。
虽然目前HuatuoGPT-o1仍处于研究阶段,尚未应用于临床实践,但其巨大的潜力已引起广泛关注。未来,随着技术的不断成熟和完善,相信HuatuoGPT-o1能够在医疗诊断、疾病预测、药物研发等方面发挥越来越重要的作用,为人类健康事业做出更大的贡献。
联系作者
文章来源:小夏聊AIGC
作者微信:
作者简介:专注于人工智能生成内容的前沿信息与技术分享。我们提供AI生成艺术、文本、音乐、视频等领域的最新动态与应用案例。每日新闻速递、技术解读、行业分析、专家观点和创意展示。期待与您一起探索AI的无限潜力。欢迎关注并分享您的AI作品或宝贵意见。
相关文章

全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。