本文从NTP范式的视角出发,全面梳理了多模态领域的最新进展。
原标题:2025年Next Token Prediction范式会统一多模态吗?
文章来源:智猩猩GenAI
内容字数:5414字
多模态智能的下一个里程碑:基于Next Token Prediction的多模态综述
本文总结了Chenllliang等人在知乎发表,并发表于arXiv的综述论文《Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey》。该综述从Next Token Prediction (NTP) 范式出发,系统地回顾了过去一两年基于NTP的多模态模型(MMNTP)在多模态理解和生成任务上的进展,涵盖了Tokenization、模型架构、训练方法、性能评估和未来挑战等多个方面。
1. 多模态Tokenization:MMNTP的基石
文章指出,多模态Tokenization是MMNTP的关键。它将图像、视频、音频等不同模态的信息分解成可供Transformer处理的Token序列。Tokenization方法分为离散型(Discrete)和连续型(Continuous)两种,前者将信息映射到有限的离散空间,后者保留数据的连续性。文中详细比较了对比学习、自编码器等多种训练方法及其在不同模态上的应用和改进,并讨论了离散型编码器中存在的编码表塌陷、信息损失等问题以及相应的改进方案(如FSQ、LFQ),以及连续型编码器(如CLIP)中语义对齐、编码效率等挑战。
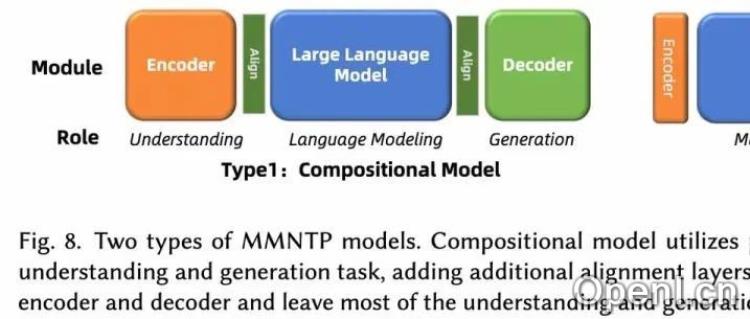
2. MMNTP模型架构:组合式与统一式
MMNTP模型通常由Transformer骨干模型、模态Tokenizer和De-Tokenizer组成。文章将MMNTP模型分为组合式和统一式两类。组合式模型依赖强大的外部编码器(如CLIP)和解码器(如SD3),而统一式模型则使用轻量级编码器和解码器(如VQVAE),将大部分任务交给骨干模型。文章对这两种架构进行了详细的比较,并以图片模态为例,展示了MMNTP模型如何统一处理图片理解、生成和编辑等不同任务,只需改变输入输出组合即可。
3. 统一的训练范式:三个阶段
将不同模态的信息转化为Token序列后,即可使用统一的MMNTP模型进行训练。训练任务分为离散Token预测和连续Token预测两种。文章将训练过程分为三个阶段:模态对齐预训练(在多模态数据-文本对上进行预训练)、指令微调(针对特定下游任务进行微调)和偏好学习(将模型输出与人类偏好对齐)。
4. 推理策略:Prompt工程
文章强调了Prompt工程在MMNTP模型中的重要性,并介绍了多模态上下文学习和多模态思维链两种方法。多模态上下文学习在输入中加入多模态任务示例,而多模态思维链则加入思维链提示(如“感知”、“推理过程”),以引导模型进行多模态推理。
5. 性能评测与挑战
文章对MMNTP模型的训练数据集进行了讨论,并比较了NTP模型和非NTP模型在多模态任务上的表现。结果表明,NTP模型在大规模理解和生成任务上均表现出色。最后,文章指出了MMNTP模型目前面临的四个挑战:如何更好地利用无监督数据、克服多模态干扰、提高训练和推理效率以及将MMNTP作为更广泛任务的通用接口。
6. 总结
该综述从NTP范式的角度,全面而系统地梳理了MMNTP模型的最新进展,为研究者提供了清晰的研究全景图,并指明了未来研究方向。
联系作者
文章来源:智猩猩GenAI
作者微信:
作者简介:智猩猩旗下公众号之一,深入关注大模型与AI智能体,及时搜罗生成式AI技术产品。
相关文章



全面、高效的AI工具产品情报,发现和使用最酷的AI工具!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。